Operating applications at scale means we have to be thoughtful and vigilant about our monitoring strategies, so we monitor everything consistently. As applications scale, it becomes increasingly important—and increasingly complicated— to effectively monitor the entire software lifecycle, from code deployment through build and deploy to alerting. So how does a fast-growing organization do it?
At New Relic, it’s all about automation. As we’ve grown to more than 50 engineering teams around the globe regularly pushing new code to production, we’ve gone from infrastructure as code to “monitoring as code,” embracing four key best practices:
- Install monitoring agents in application builds
- Add markers and tags in your deploy system
- Bootstrap applications and monitoring
- Use APIs and DSLs for dashboarding and alerting
Let’s take a closer look at each one.
Automate it #1: Install monitoring agents in application builds
Let’s start with build systems.
Modern build tools, like Gradle, can do almost anything, and you should take advantage of that power. At New Relic, we automate our build processes using the full power and expressiveness of the programming languages in which we write our applications. We use APIs and code against them within our build systems.
For example, to install the New Relic agent into a Java app, you have to download the agent, add the New Relic API as a dependency, generate a YAML config file, modify our run command, and include all that in a deployable artifact. Ok: How do we automate that?
We could write a build script that captures all the dependencies and tasks to complete the agent install, but we’d have to copy/paste this boilerplate script for every application we deploy. We’d never write actual application code like this, so why do so with build scripts?
This is where build plugins come into play. Consider this example build.gradle file:
apply plugin: ‘application’
apply plugin: ‘newrelic-agent-plugin’
apply plugin: …
application {
name 'my_app'
mainClass 'com.example.MyAppMain'
}
newrelic {
version ‘4.10.0’
includeAgentApi true
distribution {
configFilePath 'config/newrelic.yml'
agentJarPath 'agent/newrelic.jar'
}
}
…This is workable, but it’s still not ideal. We’d still need this boilerplate in all our applications, and if we wanted to, say, change something about our monitoring configurations, we’d have to update the config blocks in hundreds of build files.
So why not reach toward the nirvana of “zero-configuration builds?”
apply plugin: ‘company-java-service’
dependencies {
…
}Here we’ve written a “mega-plugin” that pulls in all the other plugins we want to use, and provides them with sensible default configurations. From here, an individual service can apply this plugin and its build dependencies, and that’s it—including monitoring is now a zero-effort default in the application’s build.
Automate it #2: Add markers and tags in your deploy system
Most modern software teams have a common, automated deploy system. Not necessarily a continuous deployment system, but a standard, centralized way to get code into production.
But you have to know when you’ve deployed that code. When something changes in your monitored data, the first question anyone asks is, “Was this related to a deploy?” There are two ways to track this information: deploy markers and version tags. Both are useful, so this isn’t an either/or choice but a both/and situation. Markers and tags provide the critical information you need to scale and automate monitoring of your deployments
Deploy markers are event logs that get recorded somewhere off to the side of your primary monitoring telemetry. They provide a chronological record of everything that’s changed across all your systems. If you want to record deploy markers, it’s usually just a matter of making a REST API call as part of your deploy process. From there, you can use a charting library or New Relic to automatically display the markers on your dashboards.
But deploy markers do have some shortcomings.
As techniques like canary deploys, phased rollouts, and blue-green deploys gain popularity, it’s increasingly hard to know exactly what a deploy marker is marking. Is it marking the start of a deploy, or the end of one? What happens if you’re halfway through a deploy and you detect a problem and need to abort and roll it back? In such situations, version tags are more useful.
At New Relic, our deploy system injects the version number into the application as an environment variable. Here’s an example of a dashboard where all our telemetry data has been tagged with the version number of the application.
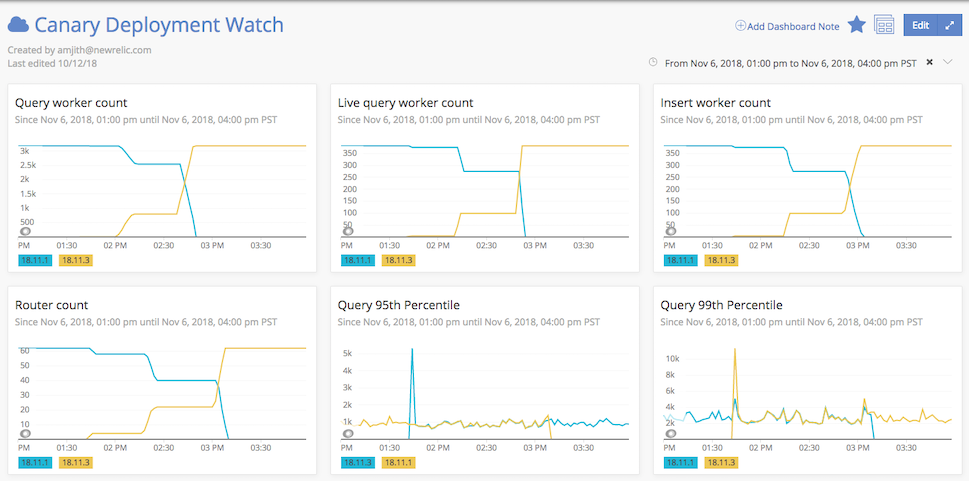
By tracking the number of instances reporting each version (in the Router count chart) we can see that this was a phased rollout over the course of 90 minutes.
And while that’s happening, we can compare performance between the versions (in the Query 95th Percentile chart) and see that, outside of a bit of Java virtual machine (JVM) warmup in the first canaries, the two versions track very close to one another, even though from minute to minute things jump around a bit based on changing workload.
We use tags to track other types of information as well. When we’re responding to an incident or a support request, we frequently need to know how to scope the problem—is the issue restricted to a single instance, or is it widespread? Often we need to compare or restrict data based on clusters or cells, or by region and availability zone, or by what team owns an application—all of which can be done with tags.
Additionally, in the containerized world, applications typically don’t know what host machine they’re running on, which can be a problem if we need to shut down a misbehaving instance. For this reason, we have our deploy system tell the container where it is running when it’s launched, so we know exactly where to look should we encounter a problem.
Your deploy system is a powerful tool, and it gives you all the information you need to know exactly where your monitoring data is coming from: which version of which application is running on which machines in which region, and so on.
Automate it #3: Bootstrap applications and monitoring
We’ve looked at how we automate the installation of monitoring agents in our application builds and monitor our deploys, so now we can look at how we automate monitoring in our applications themselves.
Earlier, I said it’s important to eliminate as much boilerplate code as you can, but the truth is you can never get rid of it all. If you have to copy/paste boilerplate code to create a new service, at least make a machine do it for you using a uniform template-based build system, like Apache Maven Archetype. When you define an organization-wide best practice to use templates to bootstrap new services, you’re taking proactive steps to ensure uniformity in your microservices architecture.
As mentioned, the New Relic deploy system injects environment variables into our applications that describe exactly what the applications are and where they’re running. But this information is of limited value unless we actually do something with it. To this end, we wrote simple wrapper libraries that allow us to attach attributes such as our applications’ names, versions, and hostnames to all the data we collect when monitoring them:
public void recordEvent(String eventType, Map<String, Object> attributes) {
// Add standard attributes
Map<String, String> envVars = System.getenv();
attributes.put("appName", envVars.getOrDefault("NEW_RELIC_APP_NAME", "unknown"));
attributes.put("version", envVars.getOrDefault("GC_VERSION", "unknown"));
attributes.put("jvmId", ManagementFactory.getRuntimeMXBean().getName());
attributes.put("ipPort", envVars.getOrDefault("CF_PRIMARY_IP_PORT", "unknown"));
attributes.put("hostname", envVars.getOrDefault("CF_FQDN", "unknown"));
attributes.put("region", envVars.getOrDefault("CF_REGION", "unknown"));
attributes.put("zone", envVars.getOrDefault("CF_ZONE", "unknown"));
attributes.put("subnet", envVars.getOrDefault("CF_SUBNET_ID", "unknown"));
NewRelic.recordCustomEvent(eventType, attributes);
}With this in place, we’re able to slice and dice the monitoring data from all of our applications along a consistent set of dimensions, even as they continue to scale.
Automate it #4: Use APIs and DSLs for dashboards and alerting
So now you’re building and deploying monitoring all your services—but that doesn’t do you much good if no one is paying attention.
With a monolithic application architecture, it may be enough to simply start creating dashboards and setting up alerts. But large microservices architectures operate at scale, and manual GUI-driven dashboard and alerting configurations are too repetitive, too error prone, and too easy to abandon. This is why modern software teams embrace APIs as first-class alternatives to GUIs.
New Relic gives you APIs to create dashboards, APIs to define synthetic monitors, APIs to set up alert conditions, and so on. But you need to decide how you’ll interact with those APIs—obviously you don’t want people manually typing out JSON payloads and cURL commands; that would barely be an improvement over making changes in a GUI. The good news, though, is that you have choices for how to approach this.
Recently, for example, IBM open-sourced a command-line tool it uses to automate management of its New Relic tasks and resources (for example, creating, editing, and deleting alert policies). This is the kind of tool you’d want to build more complicated workflows on top of; for example, you could use it to download all your existing dashboard configurations and manage those configs programmatically, essentially as templates.
In fact, this is how we manage our synthetic monitoring scripts at New Relic. New Relic Synthetics monitors are just JavaScript programs, but if you’re monitoring several clusters providing a single service, you need to update those scripts if the clusters have different URLs. With such questions in mind, we turned our Synthetics scripts into embedded Ruby (ERB) templates so that we can loop over all of our clusters and generate a unique version of the script for each cluster.
For other tasks, we embrace Domain Specific Languages (DSLs). The term “DSL” can mean a lot of things, but I’m talking about a templating or configuration language that is capable of driving an API in an automated way. At New Relic, for example, we manage our alert policies via a Ruby-based DSL:
policy "Unified Data Streams CF Alerts” do
rollup 'condition’
team_low_priority_channels
condition "WARNING Service(s) OOMing" do
type 'nrql’
query "SELECT count(*) FROM cf_docker_event where action = 'oom’”
since 2.minutes
value 'single_value’
critical above: 0, for: 1.minutes
end
endBecause this is all Ruby code, we can add loops and function calls—which makes things a little more interesting. In the example below, we loop over clusters and use the cluster identity in a few different ways: We inject the cluster name into the alert policy, and select notification channels per cluster. Notifications from the production clusters go to PagerDuty, but notifications from pre-production clusters go to email. This ensures the right people are notified for the right reasons, and no one gets woken up in the middle of the night unnecessarily.
clusters.each do |cluster|
policy "#{cluster} MyApp Lag" do
rollup 'condition'
team_alert_channels(cluster)
condition "#{sev_and_cluster('SEV3’, cluster)} MyApp" do
entities [config[cluster][‘lag_monitor_app_name']]
metric 'Custom/ConsumerLag/appendSecondsLag/my_topic/my_app'
value 'max'
critical above: 60, for: 5.minutes
end
end
endThe critical part of these configuration choices is making the right thing the easy thing. Your engineers are going to configure alert policies hundreds or thousands of times, which creates a lot of opportunities for them to take shortcuts or make mistakes. Limit those opportunities with automated management of your alert configurations—there are countless ways to do that, so find what works best for your organization. Nothing will keep your dev and ops teams up at night like wondering if something might be silently breaking and having no alerts from which to find out.
Monitoring should reduce toil
At New Relic, we obviously have plenty of opinions about monitoring modern software. But we also know that microservices architectures come with the risk of increasing toil and uncertainty in your operations. Your monitoring strategies don’t have to contribute to that toil. Using techniques like these will help you get ahead—and stay ahead—of the game as your applications and infrastructure continue to grow.

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


