AI applications are complex and distributed, making effective monitoring challenging. Combining the New Relic intelligent observability platform with Pulumi's infrastructure-as-code and secret management solutions allows for an end-to-end "observability as code" approach. This method enables teams to:
- Define artificial intelligence (AI) and large language model (LLM) monitoring instrumentation along with cloud resources programmatically.
- Securely manage API keys and cloud account credentials.
- Automatically deploy New Relic instrumentation alongside AI applications and infrastructure.
Benefits include:
- Consistent monitoring across environments
- Version-controlled observability configuration
- Easier detection of performance issues
- Deeper insights into AI model behavior and resource usage
The observability-as-code approach helps developers maintain visibility into their AI applications as they scale and evolve.
What is Pulumi?
Pulumi provides a range of products and services for platform engineers and developers, including:
- Pulumi infrastructure as code (IaC): An open-source tool for defining cloud infrastructure. It supports multiple programming languages. For example, you can use Python to declare AWS Fargate services, Pinecone indexes, and custom New Relic dashboards.
- Pulumi Cloud: A hosted service that provides additional features on top of the open-source tool, such as state and secrets management, team collaboration, policy enforcement, and an AI-powered chat assistant, Pulumi Copilot.
- Pulumi Environments, Secrets, and Configuration (ESC): This ensures the secure management of sensitive information necessary for observability. For example, you can manage New Relic, OpenAI, and Pinecone API keys and configure OpenID Connect (OIDC) in AWS. This service is also part of Pulumi Cloud.
Pulumi allows teams to version control their observability configurations and infrastructure definitions. This ensures consistency across environments and simplifies the correlation of application changes with monitoring updates and underlying infrastructure modifications.
How to achieve observability as code with New Relic and Pulumi
In this guide, you’ll add AI and LLM monitoring capabilities to an existing chat application by configuring the New Relic application performance monitoring (APM) agent, and by defining New Relic dashboards in Python using Pulumi.
The final version of the application and infrastructure referenced throughout the guide resides in the AI chat app public GitHub repository.
Before you start
Ensure you have the following:
- A New Relic account and a valid New Relic license key
- A Pulumi Cloud account
- The Pulumi CLI installed locally
All the services used throughout this guide qualify under the respective free tiers.
Explore the OpenAI demo application
The OpenAI demo application used throughout this guide is written in Node.js for the backend and Python for the frontend. It interacts with OpenAI to generate various gameplays through generative conversational AI interactions. It uses the public OpenAI platform to call its API to access different LLMs like GPT-3.5 Turbo, GPT-4 Turbo, and GPT-4o.
Below is a screenshot of a "higher or lower" gameplay:
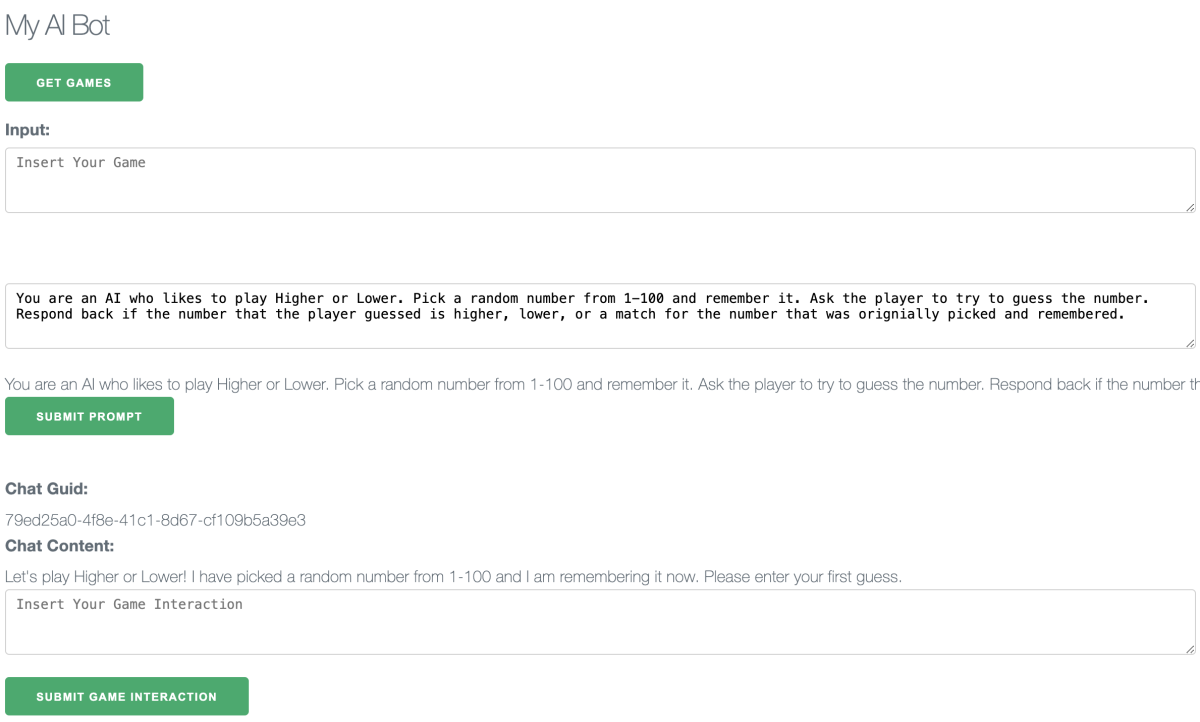
The demo simulates a retrieval-augmented generation (RAG) flow, which commonly looks up information that the AI either doesn't know or might hallucinate. The app stores a handful of common game names and instructions in a Pinecone vector database and then uses it as an embedding when calling OpenAI.
This application is configured to observe its performance, such as traces, metrics, and logs. It leverages New Relic's latest innovation in monitoring AI interactions, such as requests and responses. This capability ensures compliance, promotes quality, and observes your AI costs.
Run the app locally with Docker Compose
The easiest way to run the chat on your local machine is via Docker Compose. Inspect the docker-compose.yml file in the ./app folder and create the required .env file as shown. Then, in your terminal, run:
cd app
docker compose up \-d –build
By default, the web service will run on http://localhost:8888/.
Try out the API endpoints
The API backend provides various endpoints that expose all of its AI functionality. The frontend leverages these endpoints to simulate a flow of activity for end users to select a game and initiate a game interaction, that is, play the game, with OpenAI.
Follow these steps to simulate a higher or lower gameplay:
- Open the web service http://localhost:8888/.
- Click the Get Games button. A list of games is displayed.
- In the Input field, copy higher or lower.
- To retrieve a game prompt for the next step, click Get Game Prompt.
- To send the OpenAI request to interact with the game, click Submit Prompt.
- Enter your first guess into the Insert Your Game Interaction textbox. You’ll get a message about whether your guess was correct when compared to the number the AI picked. Repeat this step until you have guessed the correct number.
Configure New Relic agents with AI
The chat application is configured to capture telemetry using the New Relic APM agent for API and web services. This agent also leverages New Relic's latest innovation in monitoring AI interactions, such as requests and responses. This capability ensures compliance, promotes quality, and observes AI costs.
Enable the New Relic AI monitoring capabilities through the New Relic APM agent configuration or via environment variables:
NEW_RELIC_AI_MONITORING_ENABLED = TRUE
NEW_RELIC_SPAN_EVENTS_MAX_SAMPLES_STORED = 10000
NEW_RELIC_CUSTOM_INSIGHTS_EVENTS_MAX_SAMPLES_STORED = 100000
Before exploring the data streamed by the New Relic agents, you’ll use Pulumi to deploy the application to AWS and create custom dashboards. This will enable you to simulate global traffic interacting with the application, thus generating representative AI metrics to forecast performance and cost.
Manage your secrets with Pulumi ESC
While running everything locally is always a good first step in the software development lifecycle, moving to a cloud test environment and beyond involves ensuring .env files are securely available and all the application infrastructure dependencies are deployed and configured. The "Ops" side of DevOps comes into the picture, but it need not be a daunting task. You’ll leverage Pulumi ESC to manage the chat application's secrets.
Create a Pulumi ESC Environment
You'll create a Pulumi ESC environment to store all your .env secrets in Pulumi Cloud. This enables teams to share sensitive information with authorized accounts. Ensure that your New Relic license key, OpenAI token, and Pinecone API keys are handy.
In your terminal, run:
pulumi login
E=my-cool-chat-app-env
pulumi env init $E --non-interactive
pulumi env set $E environmentVariables.NEW_RELIC_LICENSE_KEY 123ABC --secret
pulumi env set $E environmentVariables.OPENAI_API_KEY 123ABC --secret
pulumi env set $E environmentVariables.PINECONE_API_KEY 123ABC --secret
Load your .env file with the Pulumi CLI
Now that you’ve defined your ESC environment, you can consume it in several ways. For instance, you can populate our .env files by opening the environment using dotenv formatting:
cd ./app
pulumi env open $E --format dotenv > ./.env
docker compose up -d –build
The Pulumi commands may be scripted to run inside an Amazon EC2 instance or AWS Fargate. Next, you’ll define AWS resources using Pulumi IaC and Python so that you can run the application in AWS. To learn more, visit the Pulumi ESC documentation.
Generate infrastructure code with Pulumi Copilot
Nowadays, you don’t need to start from scratch when using infrastructure as code. Instead, you’ll use the power of generative AI to write Python code to declare all the cloud resources needed for our chat application. This entails declaring New Relic, AWS, and Pinecone resources.
Pulumi Copilot is a conversational chat interface integrated into Pulumi Cloud. It can assist with Pulumi IaC authoring and deployment. Let's have an intelligent conversation with Pulumi Copilot to help us start writing a Python-based Pulumi program that will also have access to the previously created ESC environment.
Prompt Pulumi Copilot with:
Can you help me create a new and empty Python Pulumi project called "my-cool-chat-app" with a new stack called dev? Add "my-cool-chat-app-provider-creds" to the imports in the dev stack
Declare New Relic AI LLM monitoring dashboards
A standard method for sharing dashboards is through the JSON copy and import feature. However, importing these through the console can result in reproducibility issues over time. For example, what happens when the dashboard JSON definition changes in an undesirable way? It becomes a challenge because there are no versioning details readily available.
Instead, using a declarative approach to "import" the JSON file unlocks several benefits. It allows for managing the dashboard's lifecycle (creation, deletion, updates) through code, thereby tracking changes over time. Also, it makes it easy to incorporate into deployment pipelines and share these across teams.
You have an AI/LLM monitoring dashboard JSON file and want to use it to create a new dashboard under our New Relic account. Let's continue our chat with Pulumi Copilot and prompt it to update the current solution:
Okay great! Can you update the Python code to deploy a New Relic dashboard based on an existing JSON file I will provide as input?
Declare a Pinecone index
A Pinecone index was needed beforehand to test the chat application locally. Let's ensure its existence before deploying the chat application to the cloud.
Let's ask Pulumi Copilot to define this resource on our behalf:
Thank you! I also need a serverless Pinecone index named "games" in the "default" namespace on AWS us-east-1 with 1536 dimensions. Can you generate the Python code to define this resource?
Declare an Amazon EC2 instance
To test the chat application in a cloud environment, you'll use an EC2 instance. Let's ask Pulumi Copilot to define all the AWS resources:
Perfect! I also want to deploy my chat application to an Amazon EC2 Linux instance.
Create a VPC, security group, public subnet, and route table for the EC2 instance.
Ensure the security group allows inbound SSH traffic on port 22 from anywhere.
Ensure the EC2 instance is publicly accessible and runs a Docker Compose command to start the application.
Associate the EC2 instance with a public IP
Update the EC2 instance with a depends_on resource option for the route table association.
Deploy the application with Pulumi
You’ve asked Copilot to help with the Python infrastructure code, so it's time to deploy our application. In the chat window, expand the Pulumi Code drop-down. Click the Deploy with Pulumi button to create a new project.
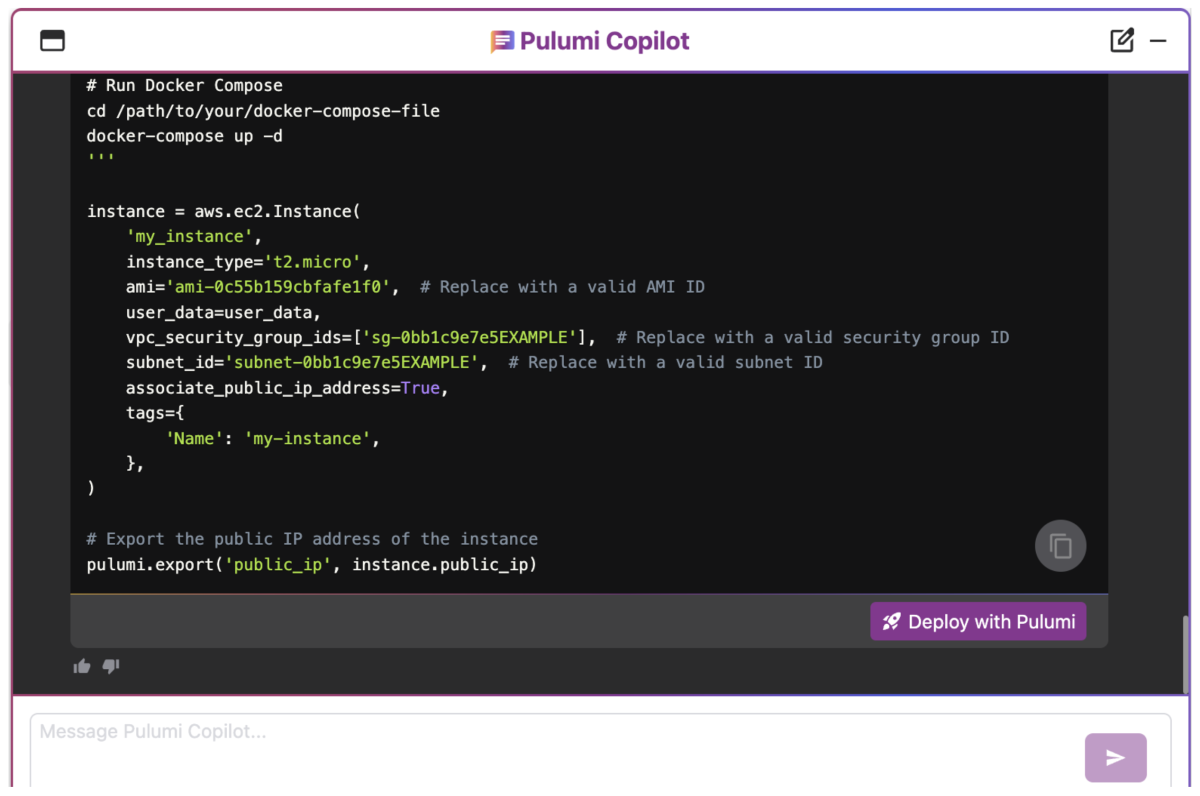
Once you download the project, you'll add credentials, modify the code slightly, and deploy our application on AWS.
- Click the Deploy with Pulumi button to create a new project. Then,
- Choose the CLI Deployment deployment method and click Create Project.
- Follow step 3 from the "Get started" steps in the next window to download the project onto your development environment.
Given that you already have a relatively small application in a GitHub repository, you’ll add a new empty folder at the root level named infra, where you'll unzip the contents of the Pulumi project. Compare your solution with the final version hosted on GitHub and fix any minor details Copilot may have overlooked.
Also, include the following changes from the final version shared:
- Update the custom user_data script.
- Update the dashboard.json to include your New Relic account id.
- Optionally, include the Docker build code to build and push the images to Dockerhub.
To learn more, visit the Pulumi Copilot documentation.
In order for Pulumi to deploy all the declared resources, it needs access to your cloud accounts. These credentials will reside in a Pulumi ESC Environment named "my-cool-chat-app-provider-creds". Refer to the README to configure the Environment and set up the Python virtual environment before deploying everything via:
pulumi up --stack dev --yes
It takes about a minute for all resources to be created. Once created, access the public URL displayed and run load tests.
Example partial output from the above command:
Type Name Status
+ pulumi:pulumi:Stack my-cool-chat-app-dev-dev created (57s)
+ ├─ newrelic:index:OneDashboardJson my_cool_dashboard created (2s)
+ ├─ pinecone:index:PineconeIndex my_cool_index created (7s)
+ ├─ docker-build:index:Image ai-chat-demo-api created (2s)
+ ├─ docker-build:index:Image ai-chat-demo-web created (3s)
+ ├─ aws:ec2:Vpc my_cool_vpc created (13s)
+ ├─ aws:ec2:Subnet my_cool_subnet created (11s)
+ ├─ aws:ec2:SecurityGroup my_cool_security_group created (4s)
+ ├─ aws:ec2:InternetGateway my_cool_igw created (1s)
+ ├─ aws:ec2:RouteTable my_cool_route_table created (2s)
+ ├─ aws:ec2:RouteTableAssociation my-route-table-association created (0.89s)
+ └─ aws:ec2:Instance my_cool_instance created (24s)
Outputs:
url: "52.41.60.240"
Resources:
+ 12 created
Duration: 1m0s
Explore your New Relic AI LLM dashboards
To recap, the chat application is configured to observe its performance, such as traces, metrics, and logs, using the New Relic APM agent and the infrastructure agent. Now that we’ve simulated traffic, let's review the collected telemetry data in New Relic.
AI Response metrics
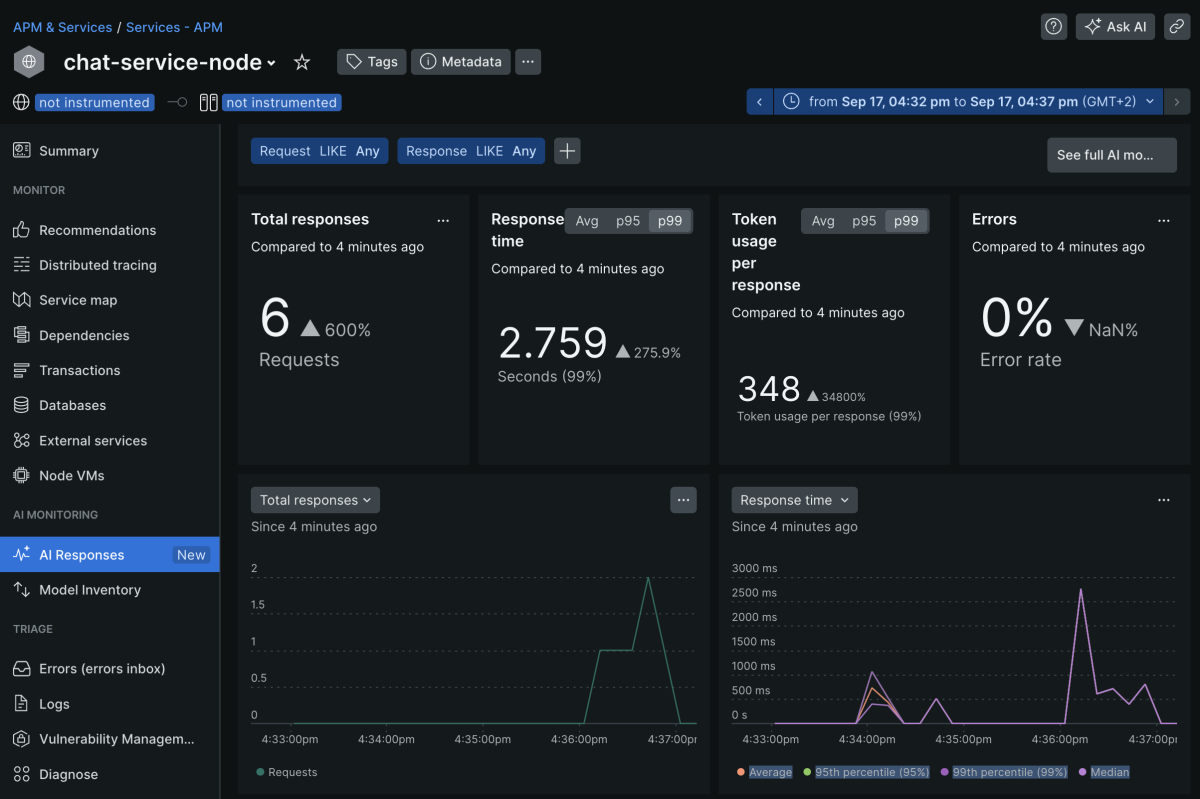
The AI Responses section will highlight key metrics when observing your AI/LLM applications. It includes data such as Total responses, Response time, Token usage per response, and Errors within your AI interactions. Time series graphs show you the same information with some more historical context.
The bottom part of that screen provides more insights into the requests and responses your end customers used to interact with the chat application.
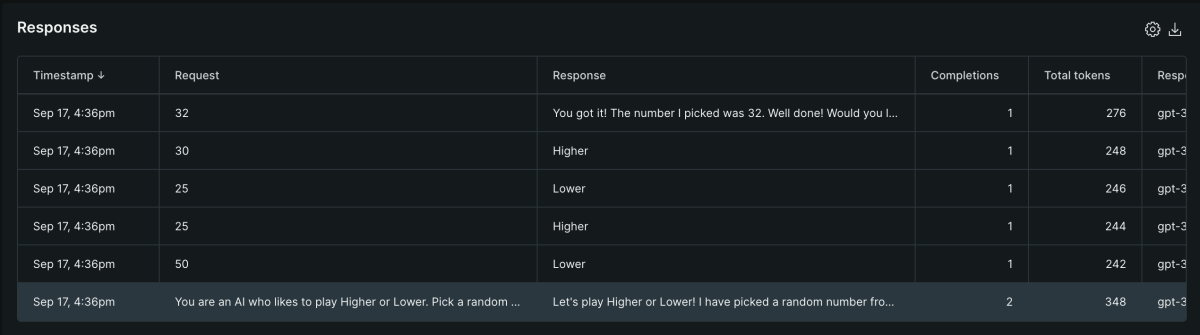
AI Model comparison
Another very important aspect of New Relic AI monitoring is the Model Inventory section.
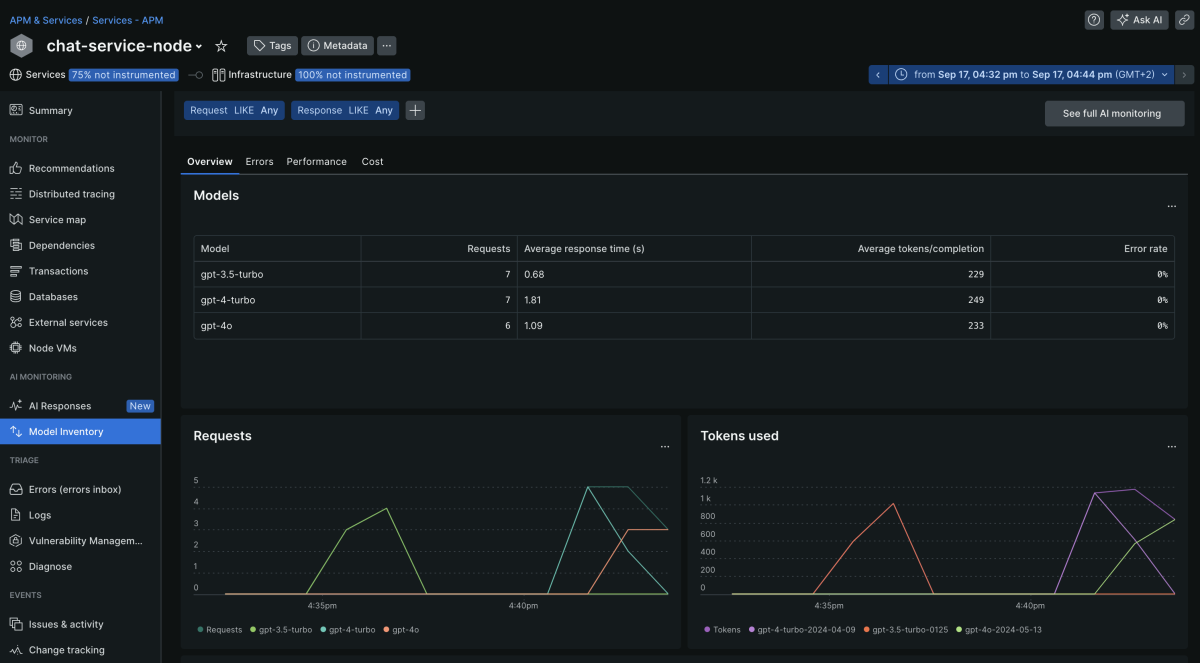
This view provides an intuitive overview of all your AI/LLM models being leveraged in our chat application. As you can see, we ran the same application with OpenAI models GPT-3.5 Turbo, GPT-4 Turbo, and GPT-4o. The AI model used is reflected in the chatModel variable for the API AI backend. This view shows you all the critical aspects of the performance, quality of responses, errors, and cost at a glance.
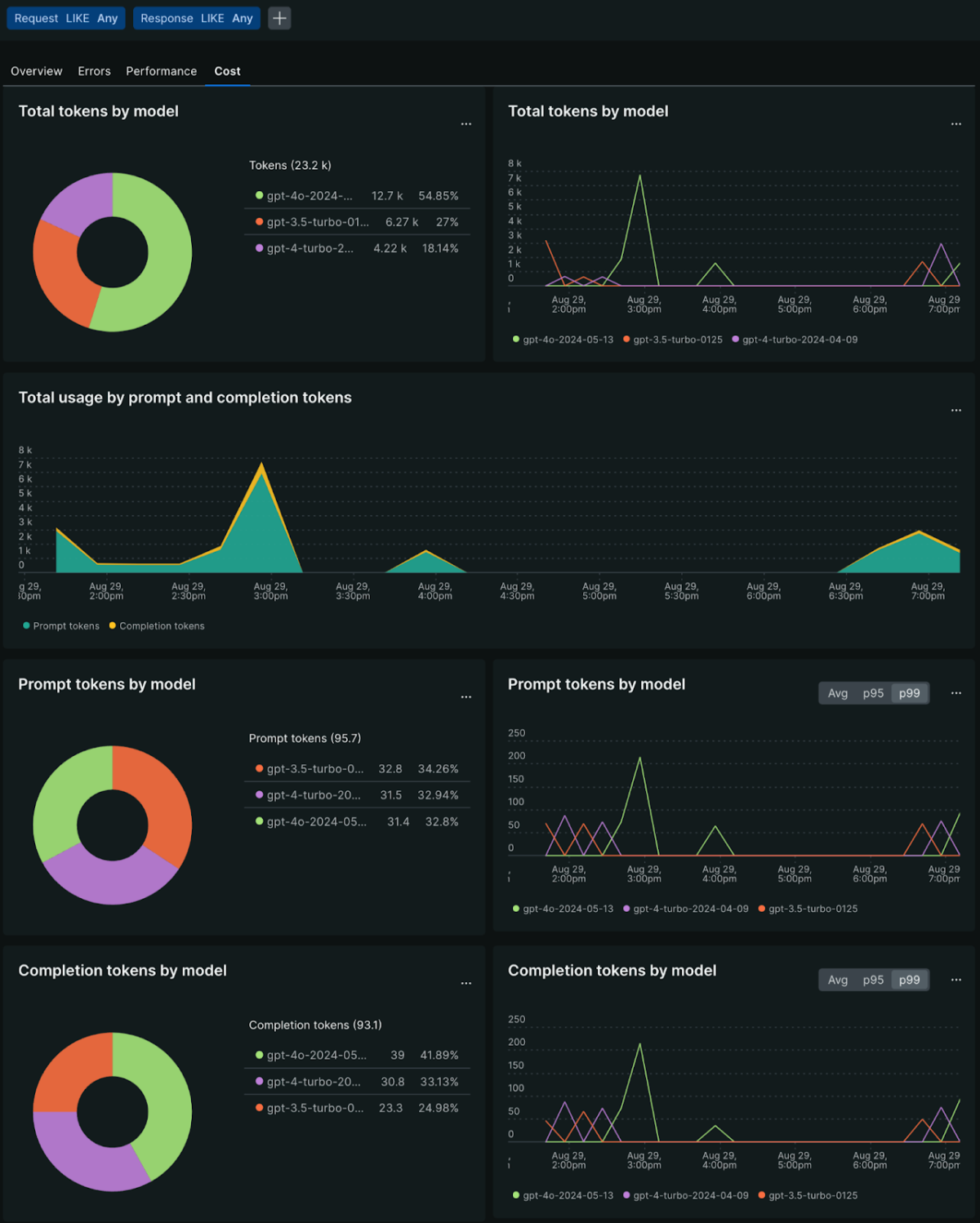
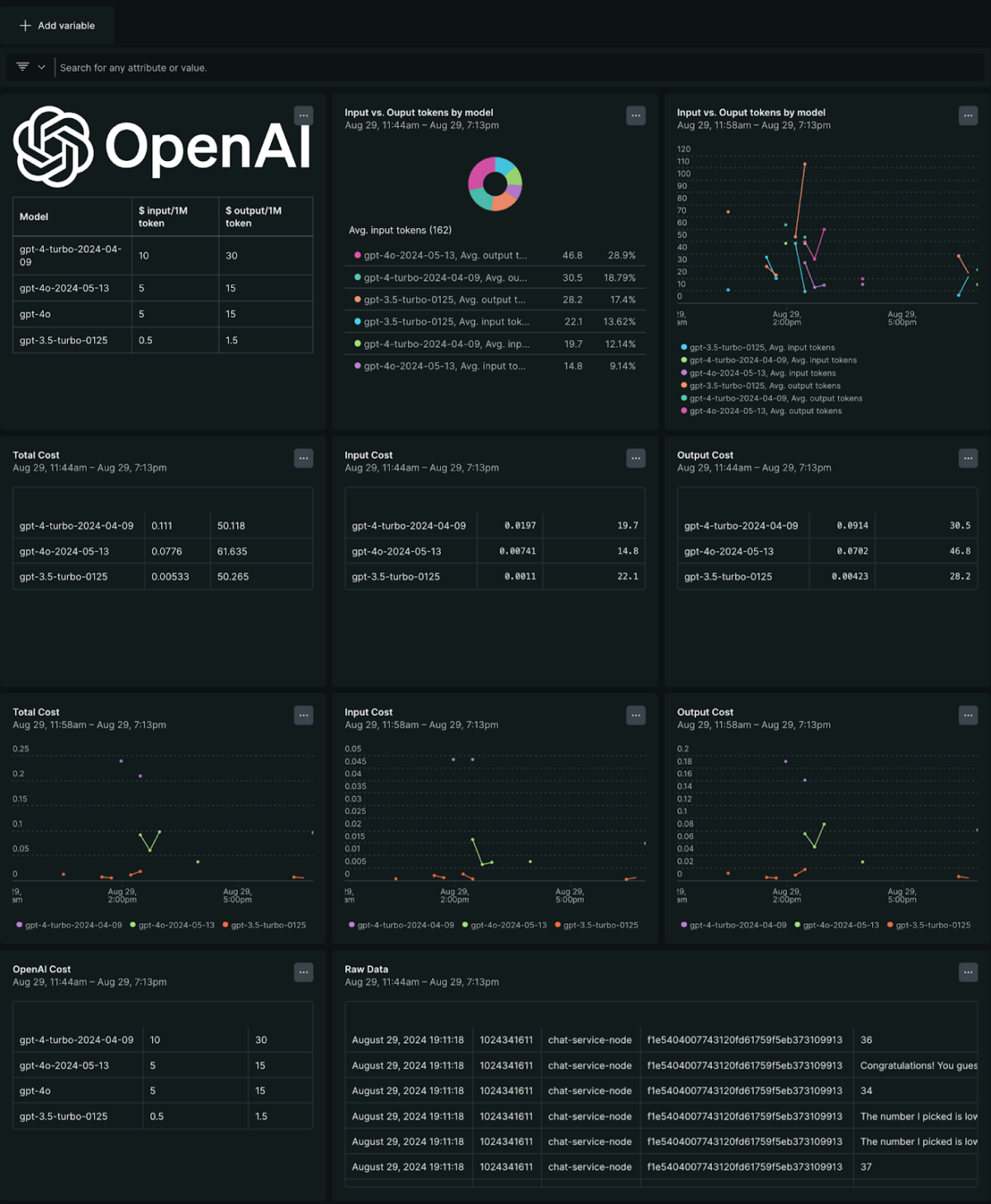
When combining the raw data from AI monitoring and custom lookup tables, New Relic also allows you to build custom dashboards (see Deploy the application with Pulumi for a reference to import custom dashboards). These custom dashboards can bring additional data, such as the actual cost (in $) for my OpenAI platform, and leverage the input and output tokens from our monitoring to calculate the total AI cost for running the chat application.
OpenAI custom dashboards
Next steps
In this guide, you explored an AI demo application powered by OpenAI and Pinecone. The application uses New Relic AI dashboards to monitor costs and other performance metrics. You used Pulimi Copilot to generate all the cloud components needed to run the chat application in AWS successfully while storing all sensitive information in Pulumi ESC.
Join us in the Observability as Code for AI Apps with New Relic and Pulumi virtual workshop, where you'll see the chat application, Pulumi, and New Relic in action.


The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.

