You can follow along with the steps in this blog post by watching the companion video: Creating Log Parsing Rules in New Relic.
Grok may be the only word in English derived from Martian. Grok was introduced in Robert A. Heinlein's 1961 science fiction novel Stranger in a Strange Land. However, in this post, I’ll focus on Grok as an industry standard for parsing log messages and how it works in New Relic.
But first, a little about how Grok parsing works in general.
To extract maximum value out of log telemetry in any platform, you need to be able to parse some unstructured messages that are often sent to your logging backend.
Consider the difference between having a log record like this…
{
“message”: “54.3.120.2 2048 0”
}...as compared to one like this:
{
“host_ip”: “54.3.120.2”,
“bytes_received”: 2048,
“bytes_sent”: 0
}An entity with three separate fields provides major observability benefits over a chunk of free text and Grok makes this kind of refinement relatively easy.
You can search for specific data in your log messages by defining a Grok pattern: %{SYNTAX:SEMANTIC}
SYNTAX is the name of the pattern that will match your text. There are some very commonly used patterns that could go in the SYNTAX log, such as NUMBER, INT, IP, and many more. The NUMBER pattern can match 4.55, 4, 8, and any other number; the IP pattern can match 54.3.120.2 or 174.49.99.1, etc. SEMANTIC is the identifier given to a matched text. If a pattern matches your text, a field with the identifier will be created in your Log record.
So if you have a log message of the form "[IP address] [Bytes Received] [Bytes Sent]" (i.e., "54.3.120.2 2048 0"), you could use the following Grok patterns to match that form and extract three useful fields:
"%{IP:host_ip} %{INT:bytes_received} %{INT:bytes_sent}"
After processing, your log record will have three new fields: host_ip, bytes_received, and bytes_sent. You can now use these fields in your observability platform to filter, facet, and perform statistical operations on your log data.
How Grok parsing works in New Relic
Parsing is applied in either the forwarding layer or the backend of the log pipeline. New Relic uses backend parsing and provides built-in parsing for certain specified log types, but you can also create custom parsing rules in our parsing UI.
Both our built-in parsing rules and custom rules use Grok patterns to specify how to extract useful information from a free text string. Parsing allows us to use advanced features like statistical analysis on value fields, faceted search, filters, and more. If we can’t classify and break down data into separate fields, we'd fall back on cumbersome full text searches with wildcards and regular expressions and less quantitative value.
Built-in Grok patterns in New Relic
Any incoming log with a logtype field will be checked against a built-in list of patterns associated with the logtype. If possible, the associated built-in Grok pattern will be applied to that log; for example:
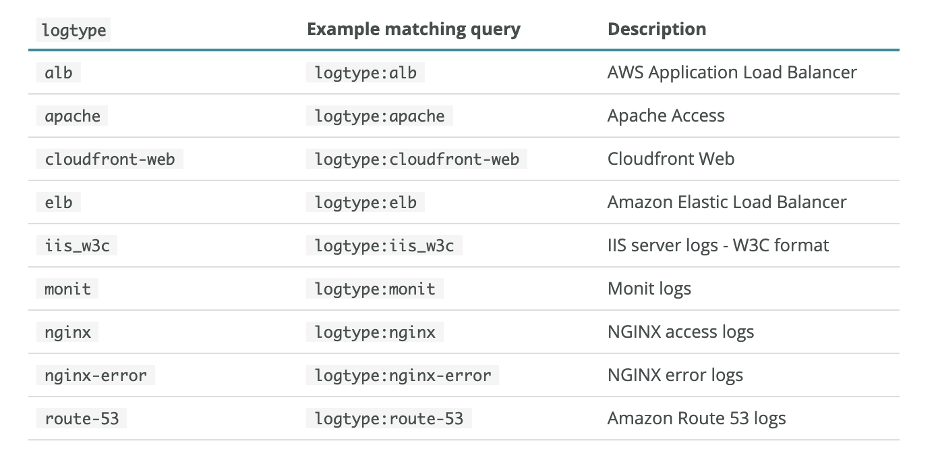
Read about New Relic’s built-in parsing in our documentation.

Creating custom Grok patterns in New Relic
If you have the correct permissions, you can use the Manage Parsing UI to create, test, and enable Grok patterns in New Relic.
Let’s say you have a microservice named “Inventory Service.” This service emits certain error logs that contain useful information in free, unstructured text.
Here’s an example:
{
"entity.name": "Inventory Management",
"entity.type": "SERVICE",
"fb.input": "tail",
"fb.source": "nri-agent",
"hostname": "inventory-host-1",
"label": "inventory",
"level": "error",
"message": "Inventory error: out of memory processing thumbnail for product 7186",
"plugin.source": "BARE-METAL",
"plugin.type": "fluent-bit",
"plugin.version": "1.1.4",
"span.id": "e2056adfcaf06c15",
"timestamp": 1598046141558,
"trace.id": "3c517a62483f66ef5943143b4165c62e"
}Again, this is useful information, but you’d like it to have more structure.
You could use a free text query to find such logs in the UI, but it would be hard to use these queries in NRQL without complex and computationally expensive regular expressions.
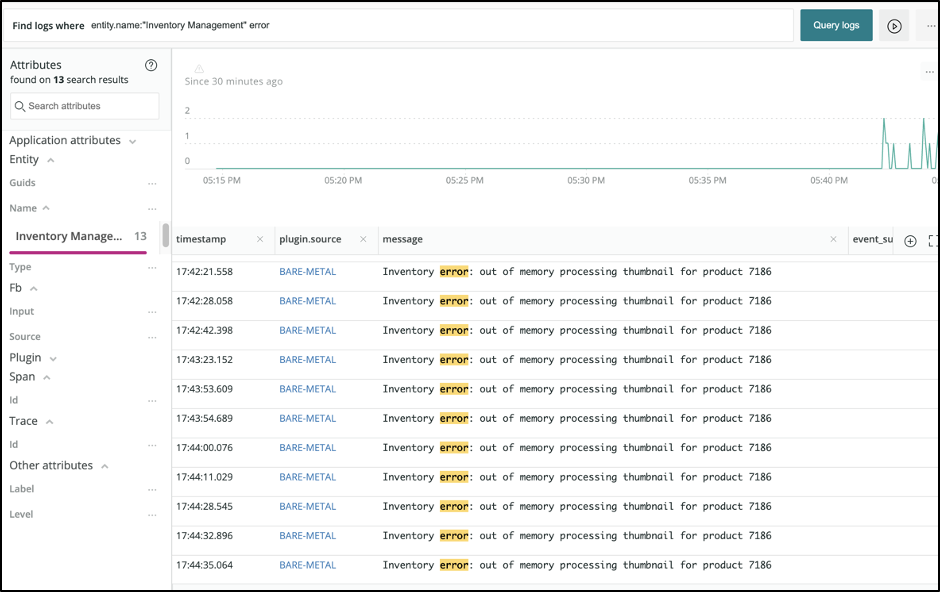
Instead, you can create a parsing rule to extract the info you need:
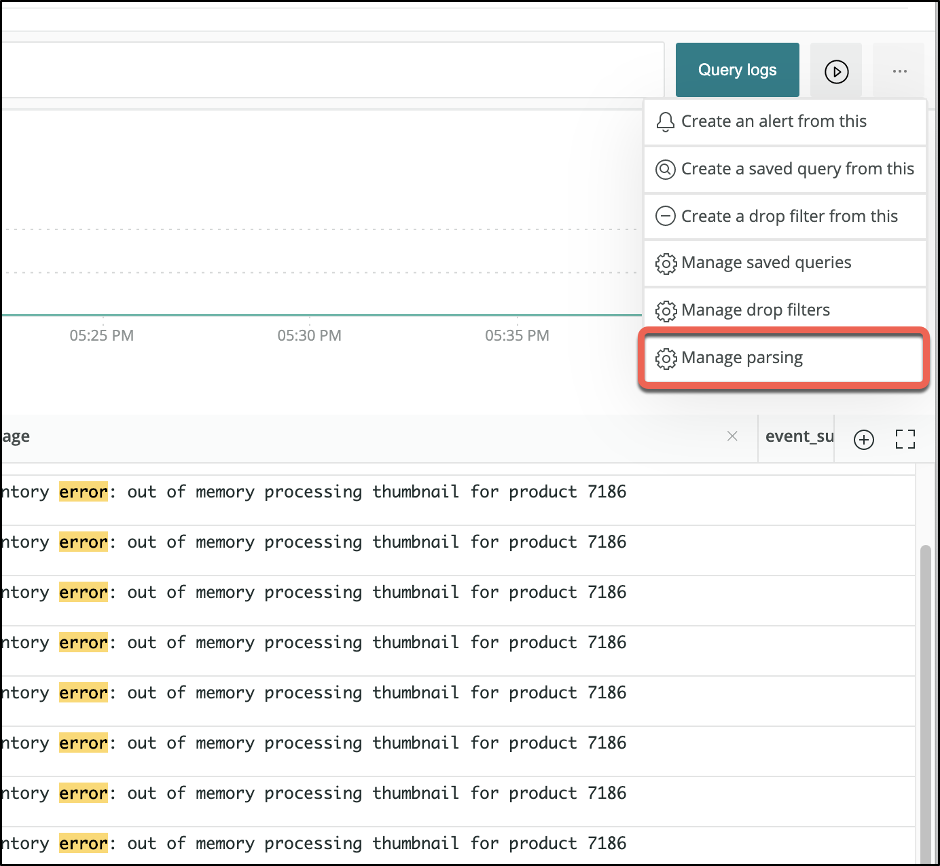
Click Manage parsing > Create New Parsing Rule and perform the following steps:
- Give the rule a useful name like “InventoryService Error Parsing.”
- Enter an Attribute/Value pair to act as a pre-filter. This will narrow down the number of logs that need to be processed by this rule, removing unnecessary processing. In this case, select the attribute “entity.name” and the value “Inventory Service.”
- Add the Grok parse rule. In this case:
Inventory error: %{DATA:error_message} for product %{INT:product_id}
- Click Test Grok and this will show you if the Grok rule matches any of the logs coming into the system.
- Now enable the rule and click Save parsing rule.
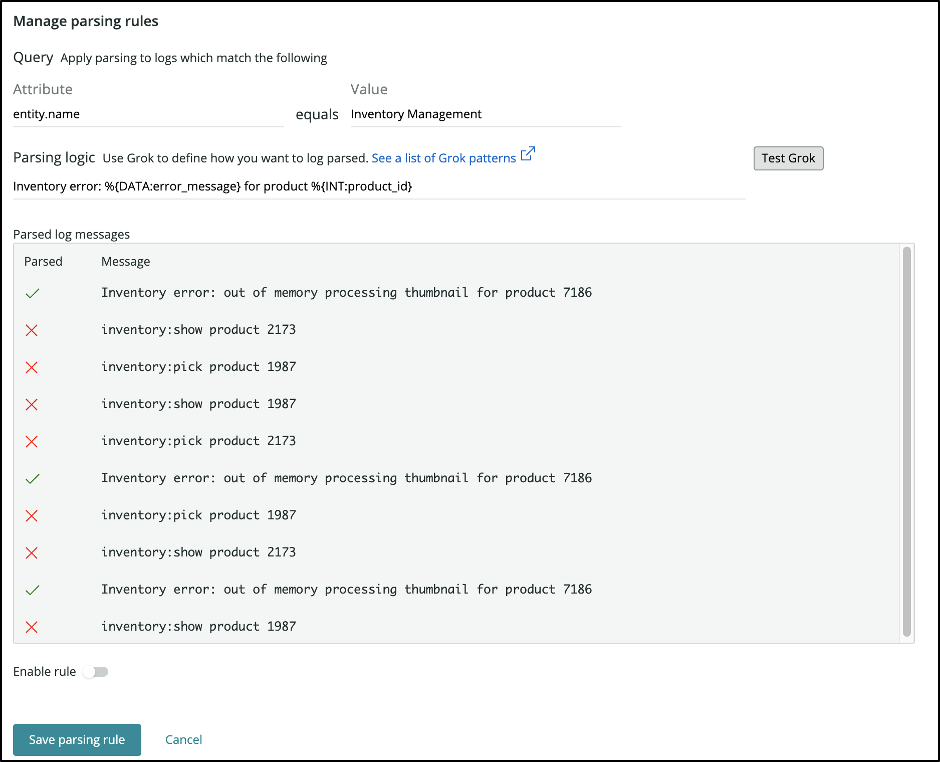
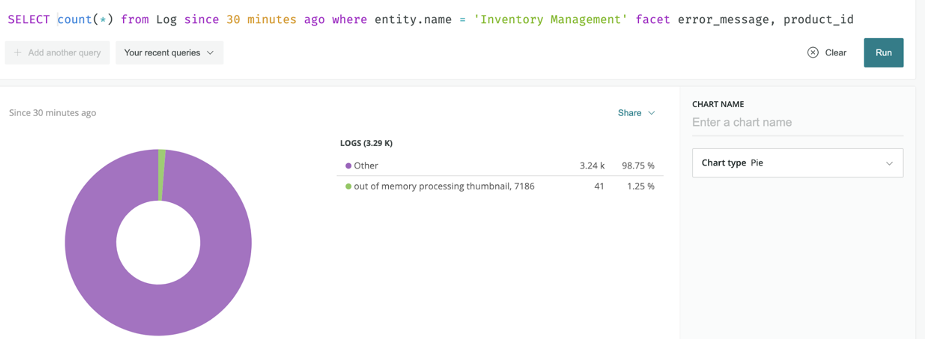
Soon you’ll see that the Inventory Service logs coming into the system are now enhanced with the addition of two new fields, error_message and product_id.
Now you can use a query to create visualization in the data explorer using these fields:
Tools and resources for developing Grok patterns
Grok Debugger is a very handy UI for experimenting with Grok patterns. Think of it as an IDE for creating production ready Grok patterns that you can use in New Relic.
Enter your example log content and the patterns you want to match:
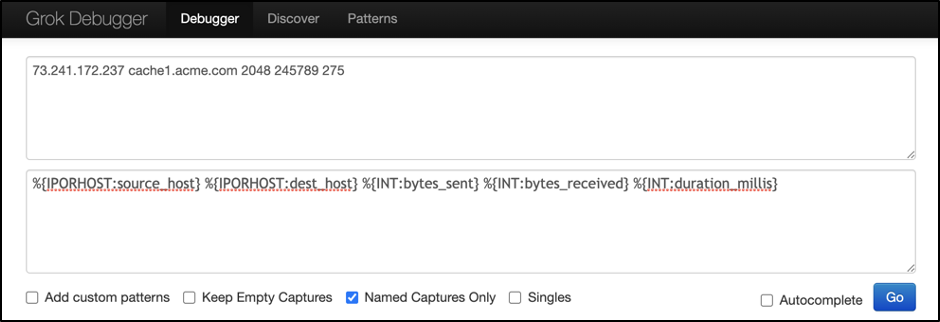
If your pattern matches the sample content, you’ll will see the extracted fields:

In terms of Syntax, here’s a subset of some of the more useful Grok patterns you may frequently need to use when working on parse rules:
| Syntax | Sample matched content (excluding quotes) |
|---|---|
| Syntax%{IP} | Sample matched content (excluding quotes)“73.241.172.237” |
| Syntax%{IPV4} | Sample matched content (excluding quotes)“73.241.172.237” |
| Syntax%{IPV6} | Sample matched content (excluding quotes)“2001:0db8:85a3:0000:0000:8a2e:0370:7334” |
| Syntax%{IPORHOST} | Sample matched content (excluding quotes)“cache1.acme.com” |
| Syntax%{INT} | Sample matched content (excluding quotes)-365 |
| Syntax%{POSINT} | Sample matched content (excluding quotes)77 |
| Syntax%{NUMBER} | Sample matched content (excluding quotes)44.5 |
| Syntax%{WORD} | Sample matched content (excluding quotes)SOMEWORD |
| Syntax%{DATA} | Sample matched content (excluding quotes)“SOME DATA” |
| Syntax%{NOTSPACE} | Sample matched content (excluding quotes)“&XYZSOMETEXT&” |
| Syntax%{SPACE} | Sample matched content (excluding quotes)“ “ |
| Syntax%{TIMESTAMP_ISO8601} | Sample matched content (excluding quotes)“2020-08-19T15:59:49.439513Z” |
| Syntax%{UNIXPATH} | Sample matched content (excluding quotes)“/tmp/mypath” |
Grok Debugger has a more complete list of Grok patterns and their underlying regular expression definitions.
Conclusion
If the message fields in your logs contain useful, human-readable information, with some obvious structure, consider normalizing that data with Grok parsing in New Relic. Doing so will make your logs first-class entities that can be queried in NRQL and used with dashboards and alerts just as you would any other events from our APM or Infrastructure Monitoring agents.
Next steps
Now that you know how to extract that kind value from your log data, sign up for a free New Relic account, and get Logs in Context as part of Full-Stack Observability.

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


