はじめに
EKS on Fargateは、Kubernetesクラスターのデータプレーンのノード管理をAWSへオフロードできる代わりに、多くの考慮事項があります。その1つがDaemon Setが使えないことです。Daemon Setは各ノードに1つのPodを配置するというKubernetesオブジェクトのひとつです。その特性上、ノード上に出力されたログを転送したりノードを経由して処理する類の役割をもつことが多いです。New RelicのKubernetes integrationもDaemon Setを使用してKubernetes Cluster Explorerを構成する情報を収集しています。つまり、EKS on Fargate環境ではNew RelicのKubernetes integrationが利用できないのです。
本Postでは、このような課題に対する解決策の1つとして、Prometheus integrationを使ってEKS on Fargateクラスターを可視化する方法をご紹介します。
Prometheus integrationという選択肢
New Relicは、Prometheusが収集したメトリクスを保存するストレージとして、Telemetry Data Platform(TDP)を利用することをサポートしています。TDPに保存したPrometheusメトリクスは、New Relicが提供する強力なクエリ言語であるNRQLだけでなく、Prometheusのクエリ言語であるPromQLも使うことができます。
PrometheusメトリクスをNew Relicに送る2つの方法
PrometheusメトリクスをNew Relicに送る方法は2種類あります。1つはPrometheusのremote_writeを使う方法、もうひとつはNew Relicが提供するPrometheus Open Metrics Integration(nri-prometheus)を使う方法です。前者は、すでにPrometheusを使用しているがデータの長期保存などストレージ管理やパフォーマンスに課題感をもたれているユーザーに最適なオプションです。後者はNew Relicが提供するPrometheus互換のパッケージです。これからPrometheusメトリクスによるモニタリングを始めたい方向けに、簡易に設定できるようになっていたり、New Relicにデータを登録しやすいようカスタマイズされています。今回はnri-prometheusを使った設定方法をご紹介します。
実現する構成
設定手順をご紹介する前に、今回実現する構成を理解しましょう。本Postでは、以下の情報を収集します。
- 各コンテナのCPU・メモリの使用状況
- kube_state_metricsが公開する各種Kubernetesオブジェクトの情報
以下がその構成とデータ収集プロセスの詳細です。
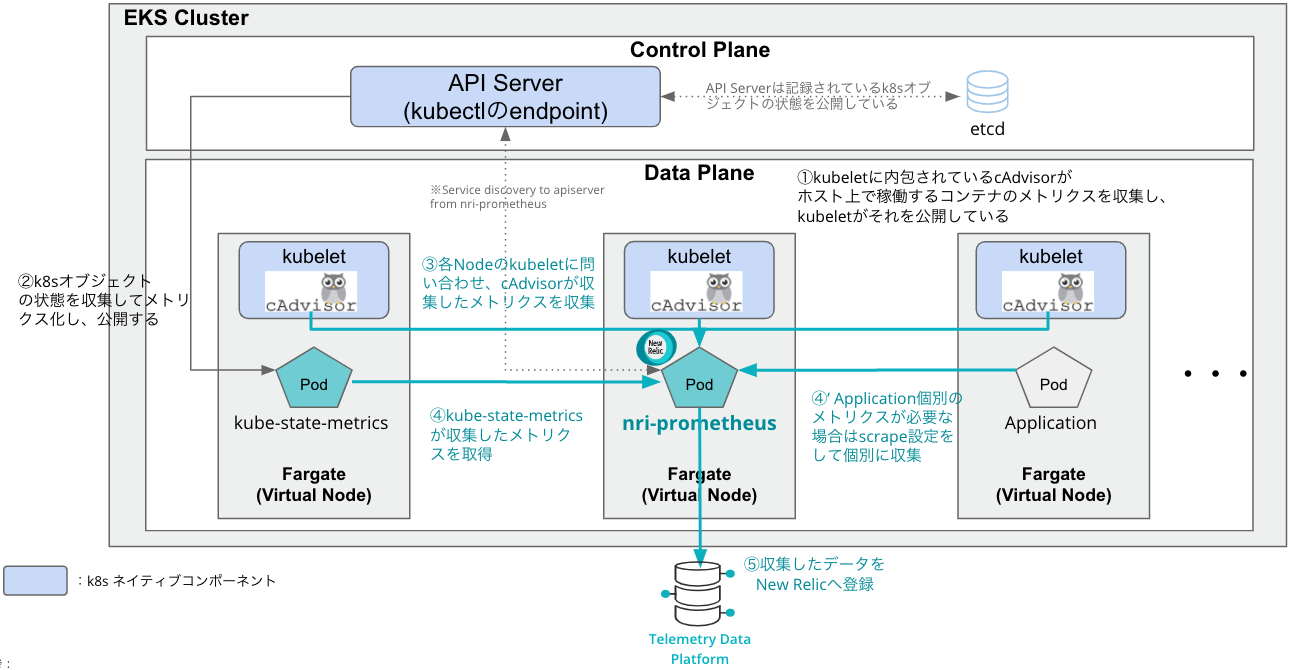
- 各コンテナのCPU・メモリの使用状況は各ノードにインストールされているcAdvisornによって収集され公開されます
- kube_state_metricsは、Kubernetesオブジェクトの様々な情報をPrometheus形式のメトリクスで公開します
- nri-prometheusは、各コンテナのCPU/メモリ使用状況を収集します
- nri-prometheusは、_kube_state_metricsのメトリクスを収集します
(この他、収集したい情報があれば独自にExporterを用意してメトリクスを公開し、nri-prometheusに読み込ませることで取得することができます(④'部分)
- nri-prometheusは、収集した各種メトリクスデータをTDPに送信します
よって、この構成を実現するにはnri-prometheusとkube_state_metricsを設定し、デプロイする必要があります。
設定手順
1. nri-prometheusの設定
それではやっていきましょう。まず、nri-prometheusをデプロイするマニフェストをダウンロードします。
curl -O https://download.newrelic.com/infrastructure_agent/integrations/kubernetes/nri-prometheus-latest.yaml
そして、以下のようにnri-prometheus-latest.yamlファイルを設定します。前述したようにノードであるFargateからコンテナのメトリクスを取得できるようにしています。
apiVersion: v1
data:
config.yaml: |
# The name of your cluster. It's important to match other New Relic products to relate the data.
cluster_name: "<YOUR_CLUSTER_NAME>"
[...]
# The label used to identify scrapable targets. Defaults to "prometheus.io/scrape".
scrape_enabled_label: "prometheus.io/scrape"
# Whether k8s nodes need to be labelled to be scraped or not. Defaults to true.
# ノードに上記ラベルがついていなくてもデータを取得しにいくようにするために、falseに変更する
require_scrape_enabled_label_for_nodes: falseそして、TDPへデータを送れるよう、クラスター名とライセンスキーの設定も行います。
env: - name: LICENSE_KEY
value: "<YOUR_LICENSE_KEY>"
[...]
config.yaml: |
cluster_name: "<YOUR_CLUSTER_NAME>"2. kube_state_metricsの設定
kube_state_metricsのマニフェストをダウンロードします。なお、バージョンはお使いのKubernetesクラスターのバージョンによって対応バージョンが異なります。詳細はこちらを確認してください。本Postではv1.9.7を使用します。
curl -L -o kube-state-metrics-1.9.7.zip https://github.com/kubernetes/kube-state-metrics/archive/v1.9.7.zip && unzip kube-state-metrics-1.9.7.zip
ダウンロードしたらnri-prometheusがkube_state_metricsをメトリクス収集ターゲットと認識させるために、ラベルを設定します。kube-state-metrics-1.9.7/examples/standard/deployment.yamlを開き、1行追加します。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.9.7
# 以下のラベルを追加する。これを追加することにより、nri-prometheusが自動的に収集対象と認識するようになる
prometheus.io/scrape: "true"
spec:
containers:
- image: quay.io/coreos/kube-state-metrics:v1.9.7
[・・・]3. kube_state_metricsデプロイ
設定が完了したkube_state_metricsをデプロイします。マニフェストをダウンロードしたディレクトリで以下のコマンドを実行します。
kubectl apply -f kube-state-metrics-1.9.7/examples/standard/
問題がなければ以下のような結果が返ります。
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created serviceaccount/kube-state-metrics created service/kube-state-metrics created
kube-system名前空間にkube_state_metricsがデプロイされます。
kubectl -n kube-system get pod --show-labels -l=prometheus.io/scrape=true NAME READY STATUS RESTARTS AGE LABELS kube-state-metrics-6c7b6d695b-qgpt7 1/1 Running 0 3m45s app.kubernetes.io/name=kube-state-metrics,app.kubernetes.io/version=v1.9.7,pod-template-hash=6c7b6d695b,prometheus.io/scrape=true
4. nri-prometheusデプロイ
いよいよnri-prometheusのデプロイします。
kubectl apply -f nri-prometheus-latest.yaml
問題がなければ以下のような結果が返ります。
clusterrole.rbac.authorization.k8s.io/nri-prometheus created clusterrolebinding.rbac.authorization.k8s.io/nri-prometheus created deployment.apps/nri-prometheus created configmap/nri-prometheus-cfg created
nri-prometheusがデプロイされます。
kubectl get pod NAME READY STATUS RESTARTS AGE nri-prometheus-67c7bccdc5-fbl8h 1/1 Running 0 93s
データの確認方法
お疲れ様でした。これで全ての設定が完了です。しばらくするとNew Relicの画面からデータを検索することができます。nri-prometheusが送信したデータはTDPのMetricに登録されます。早速クエリしてみましょう。
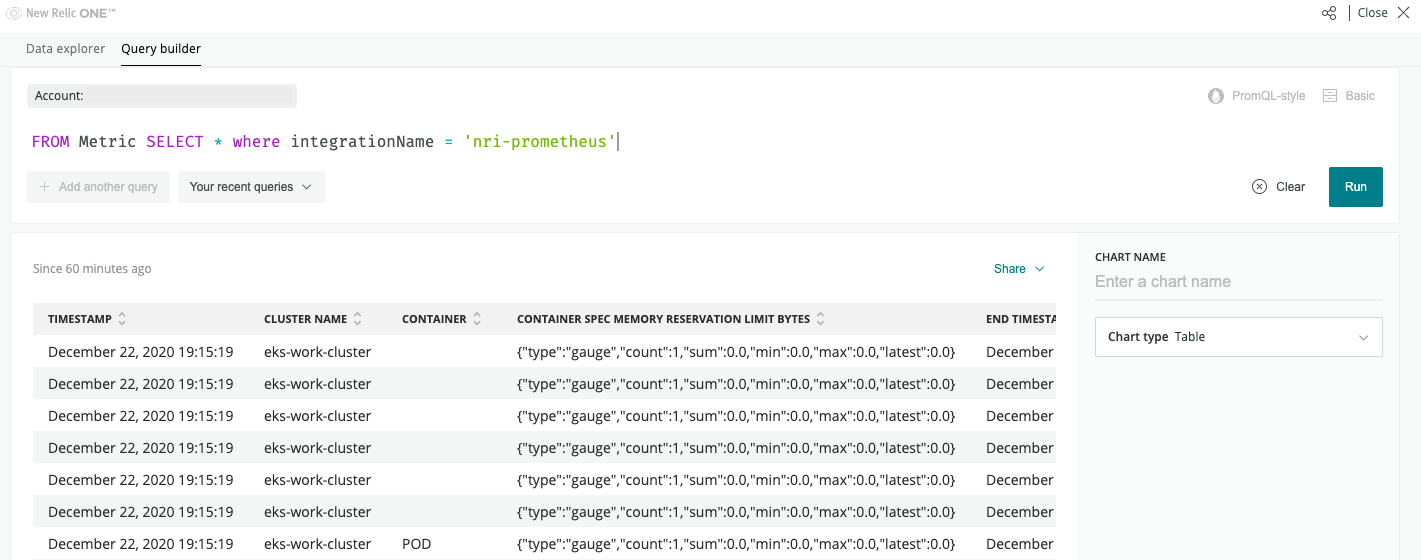
1. nri-prometheusからデータが登録されていることを確認する。
FROM Metric SELECT * where integrationName = 'nri-prometheus'
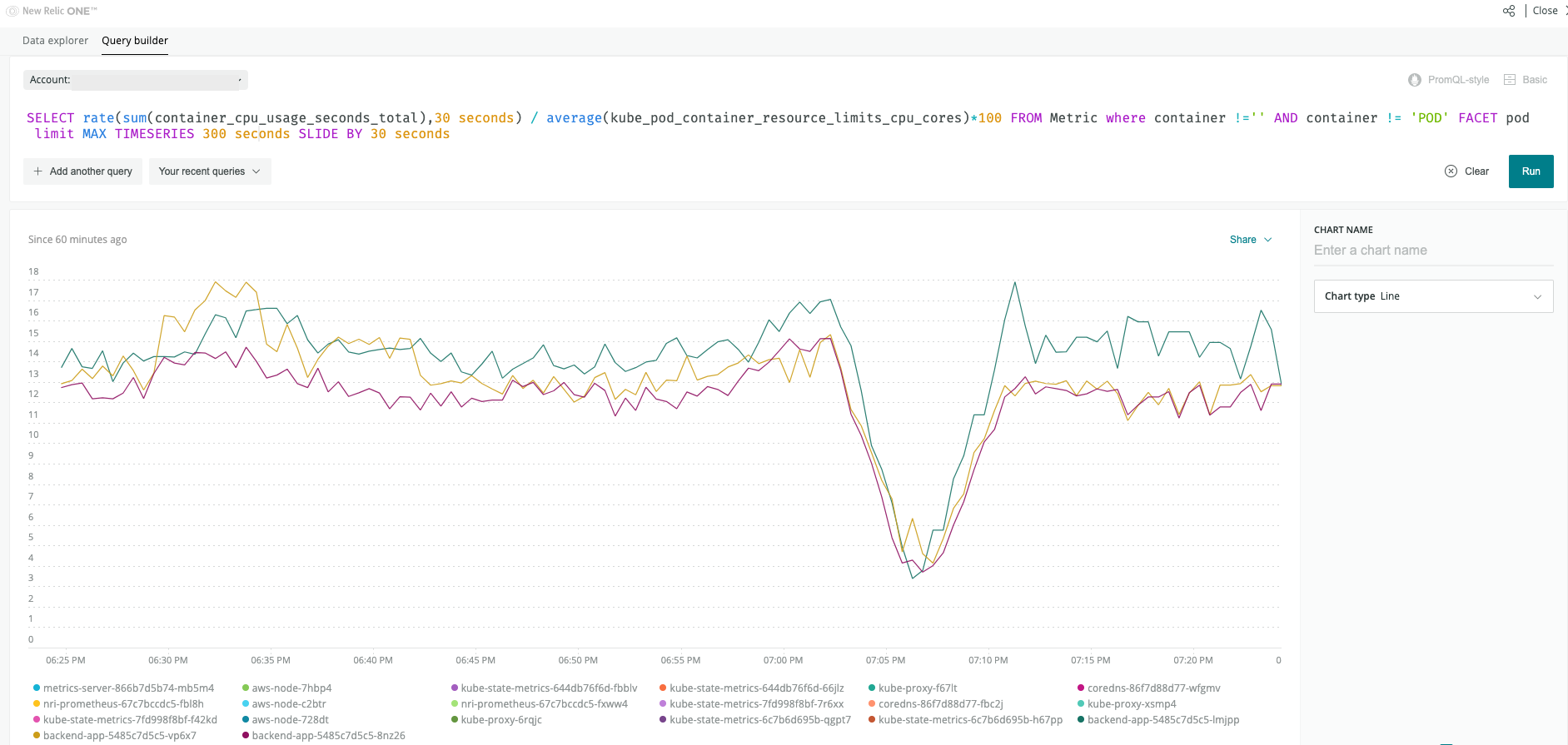
2. PodごとのCPU使用率を求める
次に、各PodのCPU使用率を求めてみます。以下のクエリは、cAdvisorから取得できるcontainer_cpu_usage_seconds_totalとkube_state_metricsから取得できるkube_pod_container_resource_limits_cpu_coresという2つのメトリクスを使って計算し、ラインチャートとして表現しています。
FROM Metric SELECT rate(sum(container_cpu_usage_seconds_total),30 seconds) / average(kube_pod_container_resource_limits_cpu_cores)*100 where container !='' AND container != 'POD' FACET pod limit MAX TIMESERIES 300 seconds slide by 30 seconds
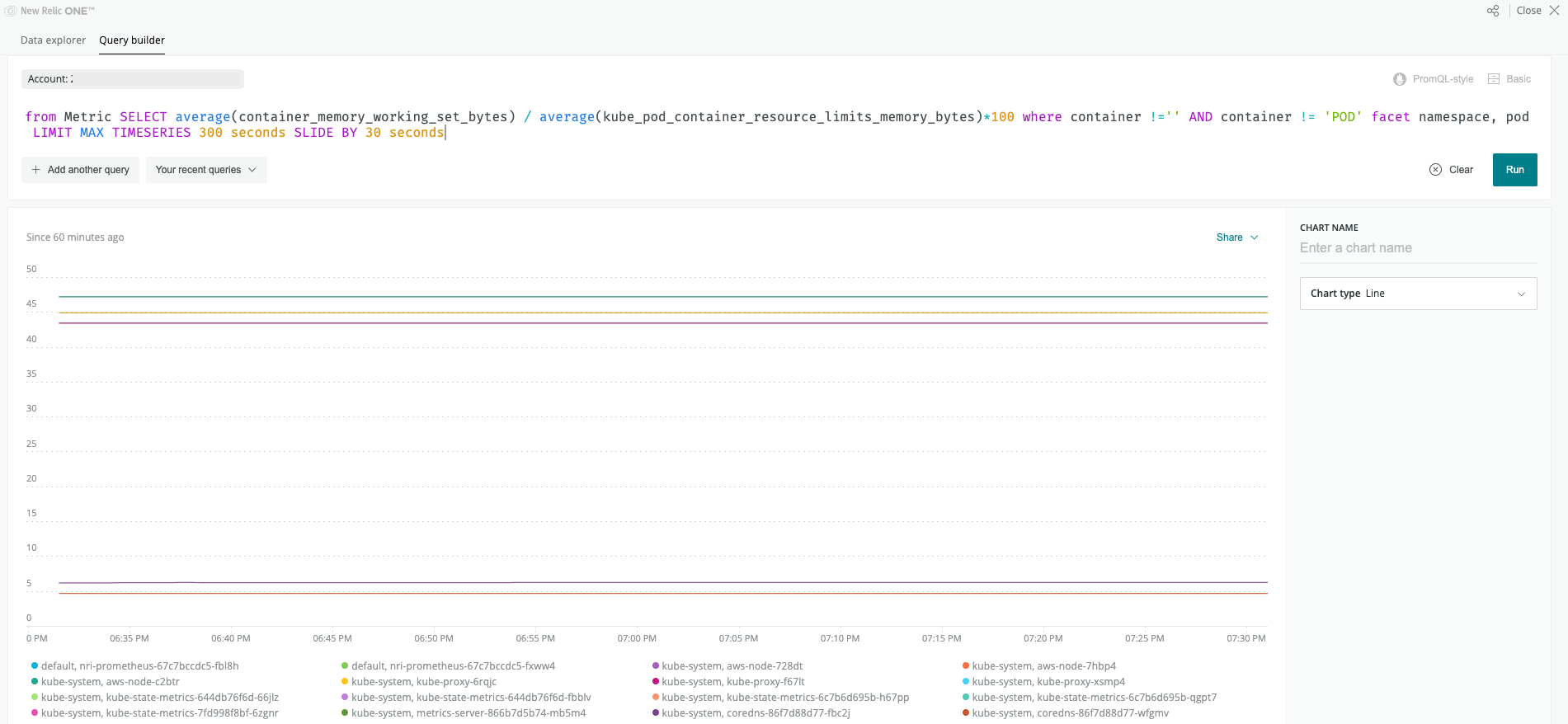
3. Podごとのメモリ使用率を求める
メモリ使用率も同様に、cAdvisorから取得できるcontainer_memory_working_set_bytesと、kube_state_metricsから取得できるkube_pod_container_resource_limits_memory_bytesを使って計算することで、表現することができます。
FROM Metric SELECT average(container_memory_working_set_bytes) / average(kube_pod_container_resource_limits_memory_bytes)*100 where container !='' AND container != 'POD' facet namespace, pod LIMIT MAX TIMESERIES 300 seconds SLIDE BY 30 seconds
Prometheusデータに対するクエリ方法は公式Documentで紹介しています。ご紹介したクエリ以外にも、Podのステータス状況を追跡して問題がないかを可視化したりすることも可能です。ぜひ色々な情報を可視化してみてください。こんなことできないの?ということがありましたら、ぜひ弊社までお問い合わせください。
まとめ
New RelicはKubernetes integrationという強力なソリューションを提供していますが、残念ながらFargateでは使うことができません。しかし、Prometheus integrationをkube_state_metricsと合わせて使用することで、クラスター状態を可視化することができます。また今回ご紹介したソリューションは、FargateだけでなくEc2タイプのクラスターでもご利用いただくことが可能です。すでにProthemeusで多くのExporterを利用しているが、データ保管に悩んでいる方は、ぜひデータストア先をNew RelicのTDPに向けてみてはいかがでしょうか?TDPはとても高速かつ安価なデータベースです。運用のための運用を削減する手助けになるはずです。
さらに、TDPはGrafanaのデータソースとしても機能します。PromQLもサポートしていますので、クエリ変換のコストなく使い慣れたGrafanaでTDPのデータを可視化することも可能です。こちらについては別途ご紹介したいと思います。
いかがでしたか?New Relicでは様々なパターンでご利用のお客様に最適なソリューションを提供しています。ご自身のユースケースではどのようなことができるか、ぜひ一度ご相談ください。

本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


