このBlogはHow To Set Up Logs In Context For A Java Application Running In Kubernetesの意訳です。
ソフトウェア開発者、DevOpsエンジニア、およびITプロフェッショナルにとって、ログデータはトラブルシューティングにおいて貴重でかけがえのないソースです。今日、チームはかつてないほど多くのソースからのより多くのログデータで溢れています。さらに、ログデータの量が増えると、このデータの収集、管理、分析に伴う課題も大きくなっていきます。
New Relic Logsは、高速で信頼性が高く、非常にスケーラブルなログ管理でそれを簡素化します。開発者と運用チームは、イベントやエラーなどのアプリケーションおよびインフラストラクチャパフォーマンスデータをより深く可視化できるようになります。ログデータをメトリック、イベント、トレースなどのテレメトリデータと関連付けることで、本番環境のインシデントを迅速にトラブルシューティングすることができ、平均解決時間(MTTR)が短縮されます。
New Relicを使用すると、Fluentd、Fluent Bit、Logstash、Amazon CloudWatchなどの最も一般的なオープンソースログツールと統合するプラグインを使用して、ログデータを簡単に収集して視覚化できます。
New Relic logs in contextを使用すると、コンテキストデータをログエクスペリエンスに取り込み、ログデータを他のテレメトリと関連付けて、アプリケーションおよびインフラストラクチャの有意義なパターンと傾向を明らかにできます。
Logs in contextとは何か?
Logs in contextは、ログデータとNew Relic APMのエラーやトレース情報などの関連データとリンクするためのメタデータを追加します。すべてのデータを関連づけることで、問題の根本原因をより迅速に把握できます。すべてのログから、問題を特定して解決するために必要な正確なログの該当行まで絞り込みます。たとえば、ログメッセージを関連するエラートレースまたはJavaアプリケーションの分散トレースに関連付けることができます。
このブログ投稿では、Kubernetesクラスターで実行されているJavaアプリケーションでLogs in conntextを設定する方法について説明します。これは、3つのステップで実現します。
- Kubernetes integrationをインストールする
- Kubernetesロギングを構成する
- JavaアプリケーションでLogs in contextを有効化する
それでは始めましょう!
step1. Kubernetes integrationをインストールする
New RelicのKubernetes integrationにより、クラスターのパフォーマンスに関する詳細な情報が提供されます。ノード、名前空間、デプロイメント、レプリカセット、ポッド、およびコンテナーに関するデータとメタデータに関するレポートが提供されるため、問題が発生した場合の発生箇所や影響範囲を簡単に特定できます。
この例では、Kubernetes環境はスタンドアロンですが、Amazon Elastic Kubernetes Service(EKS)、Google Kubernetes Engine(GKE)、Red Hat OpenShiftなど、クラウドベースのKubernetesプラットフォームもいくつかサポートしています。
- New Relicは、kubernetes APIサーバーをリッスンし、メトリックを生成するkube-state-metricsを使用して、Kubernetesオブジェクトの状態に関する情報を収集します。次のコマンドを使用して、クラスターにkube-state-metricsをインストールします。
curl -L -o kube-state-metrics-1.7.2.zip https://github.com/kubernetes/kube-state-metrics/archive/v1.7.2.zip && unzip kube-state-metrics-1.7.2 .zip && kubectl apply -f kube-state-metrics-1.7.2 / kubernetes
- New Relic Kubernetes integrationの構成ファイルをダウンロードします。
curl -O https://download.newrelic.com/infrastructure_agent/integrations/kubernetes/newrelic-infrastructure-k8s-latest.yaml
- 構成ファイルの
env:セクションに、New RelicのライセンスキーとKubernetesクラスタを識別するため、クラスタ名を設定します。
env: -名前:NRIA_LICENSE_KEY 値:<YOUR_LICENSE_KEY> -名前:CLUSTER_NAME 値:<YOUR_CLUSTER_NAME> - クラスターに適用します。
kubectl apply -f newrelic-infrastructure-k8s-latest.yaml
- one.newrelic.comに移動し、Kubernetesクラスターエクスプローラーランチャーを選択します。これにより、Kubernetesクラスターエクスプローラーが表示されます。以前に使用したことがない場合は、数分かけて探索してください。それだけの価値があります。

ヒント:問題がある場合、またはクラスターが表示されない場合は、Kubernetes integrationのドキュメントをご覧ください。
step2:Kubernetesロギングを構成する
次に、Kubernetesログを収集して、New Relicに送信します。ここでは、FluentBitとNew Relic出力プラグインを使用してこれを行います。設定方法は次のとおりです。
- GitHubからNew Relic kubernetes-loggingプロジェクトをcloneまたはダウンロードします。
new-relic-fluent-plugin.ymlのenv:セクションを編集して、プレースホルダーの値<LICENSE_KEY>をNew Relicライセンスキーに置き換えます。
-名前:LICENSE_KEY 値:<YOUR_LICENSE_KEY>
- ロギングプラグインをKubernetes環境に適用します。
kubectl apply -f .
- one.newrelic.comへアクセスし、ログのランチャーを選択します。しばらくすると、Kubernetesログエントリが表示されるようになります。他のソースからのログエントリを既に取得している場合は、クエリフィールドに
plugin source: “kubernetes”を追加します。これにより、Kubernetesクラスターからのエントリのみが表示されます(おめでとうございます。これでNew Relic Logsを使用した貴重な経験を得ました。クエリはシンプルで簡単です。結果を待つ必要も、学習する特別なクエリ言語もありません。)

New Relic Logsはクラスターからログデータを収集します
ヒント: 問題が発生した場合やログが表示されない場合は、Kubernetesプラグインに関するドキュメントをご覧ください。
step3:JavaアプリケーションでLogs in contextを有効化する
これを機能させるために、New Relicにログエントリをアプリケーションアクティビティにマッピングするメタデータを注入する必要があります。New Relicは既存のアプリケーションログフレームワークを活用してそれを行います。この手順には構成の変更が含まれますが、アプリケーションコードを変更する必要はありません。
この例では、JavaアプリケーションのロギングにLog4j 2.x拡張を使用していますが、New Relic は他の言語とロギングフレームワークもサポートしています。
- New RelicのJava APMエージェントv 5.6.0以降を使用し、Distributed tracingを有効化します。
- New Relic logs in contextの拡張機能をプロジェクトに追加します。私のプロジェクトはGradleを使用しているため、次のように
dependenciesセクションにcompileスタンザを追加しました。
dependencies { compile("com.newrelic.logging:log4j2:1.0-rc2") } - ロギング構成ファイル(この例では
log4j2.xml)を編集して、packagesステートメントを<Configuration>タグに追加します。
<Configuration xmlns = "http://logging.apache.org/log4j/2.0/config" packages = "com.newrelic.logging.log4j2">
- ロギング構成XMLファイルで、
<NewRelicLayout />;を追加します。ログアペンダーの1つにタグ付けします。この場合、コンソールアペンダーを使用します。これは、Kubernetesでログを集約するためのデフォルトの方法であるためです。
<Appenders> <Console name="STDOUT" target="SYSTEM_OUT"> <NewRelicLayout/> log4j2.messageFactoryを使用するようにシステムプロパティNewRelicMessageFactoryを設定します。これを行うには、カスタムコマンドをJavaコマンドラインに追加します。
-Dlog4j2.messageFactory = com.newrelic.logging.log4j2.NewRelicMessageFactory
ヒント:これらのステップで何をする必要があるかを理解しやすくするために、Build.Gradleおよびlog4j2.xmlファイルの例を確認してください。
- アプリケーションをKubernetes環境に再デプロイします。
- 数分待ってから、
span.idまたはtrace.id属性を持つログエントリを探します。たとえば、クエリフィールドにhas span.idを追加します。ヒント:トラフィックが表示されない場合は、アプリを実行してください。
これで、Cluster ExplorerからPodを選択するとSee logsボタンが表示されますので、クリックすると該当Podのアプリケーションログを表示することができます。
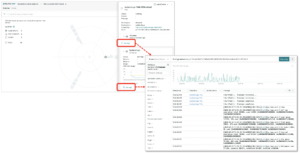
また、該当PodのTrace this applicationをクリックするとDistributed tracing画面に遷移し、そのPodに関連するログに素早くたどり着くことができます。
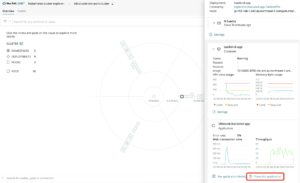
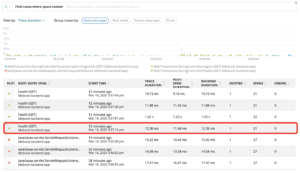
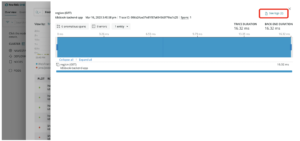
クラスタエクスプローラを使用してKubernetes環境を最新の状態に保つ方法について詳しく知りたいですか?New RelicでKubernetesを監視するための完全な紹介や関連ポストご覧ださい。

本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


