こちらのポストは Site Reliability Engineering - Philosophies, Habits, and Tools for SRE Success の意訳です。
SREってなんだ?
デジタルビジネスで成長する企業が安定性と信頼性の改善、そして自動化を推進する方法を模索するにつれ、開発者と運用エンジニアの責任はますます重要になってきています。システムの規模に応じて手動による介入を少なくし、ダウンタイムを削減するために多くの組織でサイト・リライアビリティ・エンジニアリング(以下SRE)が形成されています。
「サイト・リライアビリティ・エンジニアリング(SRE)」というフレーズは、Googleのエンジニアリング担当副社長であるBenjamin Treynor Sloss氏の功績によるものです。Sloss氏は2003年にGoogleに入社し、Googleの本番システムの健全性を大規模に確保するためのチームの構築を任されました。Sloss氏によればSREは「ソフトウェアエンジニアに運用機能を設計するように依頼すると起こりうること」と述べています。SREは従来、開発、運用、およびその他のITグループが責任を負っていた職域を超えた役割なのです。
SREの急増
SREの役割は明らかにますます多くの企業に拡大しています。この記事の執筆時点で、Glassdoorの最近の求人検索で61,600を超えるSREのオープンポジションが生み出されました。ハイテク企業においては確かにSREはとても多く求められています。AdobeからGitHub、Spotifyおよびその他の企業はすべてSREを採用しています。
あらゆる形や規模の企業がSREを採用し始めていることは驚くことではありません。New RelicのSREチームのソフトウェアエンジニアであるBeth Longは、次のように述べています。
「GoogleとNetflix、AmazonとHeroku、これら大企業はSREをもともと持っていましたが、最近ではSREが必要だと気づく中小企業が現れ始めています。」
そのような背景の中でSREの役割に適した才能と経験を兼ね備えた人々の需要は高まっています。TechCrunch で「サイト信頼性エンジニアは次のデータサイエンティストか?」と取り上げられたり2017年にはLinkedin では SREを技術分野で最も有望な仕事の1つとして取り上げました。
また、Sloss氏のチームはSREに関する本を執筆しています。DevOpsの世界で最新のSREプラクティスがどのようなものか疑問に思っているのであれば、Google Site Reliability Engineeringの本は素晴らしい参考資料です。その本の中では「システム、特に大規模で動作する複雑なコンピューティングシステムをどのように実行すべきでしょうか?」と問いかけています。Googleの答えは「従来の組織でIT運用担当者が通常処理していた作業を、ソフトウェアエンジニアが行うこと」でした。「当社のSREチームは、ソフトウェアエンジニアを雇って、通常は手動でシステム管理者が実行する作業を遂行することに焦点を当てています」とSloss氏は説明します。
SREの職務と日々のタスクは会社によって異なりますが、その役割の有用性は明らかです。会社でSREの実践方法をまだ考えている場合でも、もしくは既存のSREチームのプロセスと習慣を改善しようとしている場合でも、Googleのような大企業のケースは、中小規模の企業でも同様に機能するとは限りません。そのため、この記事では、SREの成功の哲学、習慣、およびツールをNew Relic自身の定義、ガイドライン、および役割に対する期待を記載しようと試みています。
1.SREの哲学と原則
SREは”DevOpsを純粋な形にしたもの”なのか
SRE担当VPとして、Matthew FlamingはNew RelicのSREプラクティスを監督しています。SREはおそらく”DevOpsの原則を単一の役割に最も純粋に蒸留したものだ”と彼は考えています。
昨年の FutureStack New YorkでGoogleのSREであるLiz Fong-Jones氏はこの考えを広げました。Googleのソフトウェアエンジニアは、運用システムのコードと信頼性に常に責任を負っていますが”SREはさまざまなシステムがどのように連携するか、どのように機能するか、そしてどのように改善されるべきかについて、専門的な理解を深めることに責任がある”と彼女は言いました。SREはソフトウェアエンジニアリングのタスクを引き受ける可能性がありますが、エンジニアリングチームが提供するサービスの労力を削減し、信頼性を向上させるための自動化プラクティス拡大も担当します。基本的な目標は「システムの規模が拡大しても、手動による介入を少なくして信頼性を高める」ことにあります。
スケーリングの2つの軸
ソフトウェア組織がスケーラビリティについて計画しなければならないポイントには2つの軸があります。最初の軸は「ワークロード (WORKLOAD)」です。物理ホストまたは仮想マシン、およびそれらで実行されるサービスに合わせて効率的にスケールする必要があるリソースの数です。2番目の軸は「複雑さ(COMPLEXITY)」です。サービスと組織の成長との間の依存関係の数です。基本的にSREは両軸のスケーラビリティを可能にすることを目指します。
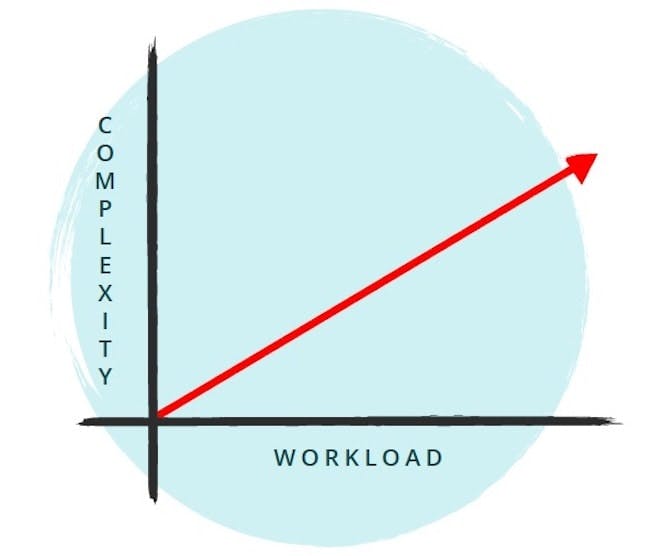
Bigtableデータベースサービスに取り組んでいたFong-Jones氏は、2009年頃のGoogleが学んだ教訓に基づいてこの考え方を支援しています。当時、Bigtableを会社全体で共有サービスとして実行するために多くの手作業が必要でしたと彼女は述べています。フットプリントはまだ比較的小さいものでしたが、スケーリングに問題があることがすぐに明らかになりました。非SRE(または非DevOps)としての解決策は「この課題を処理するために、さらにシステム管理者を雇おう」でした。しかし、そのアプローチは、実際には長期的に解決には繋がらずより多くの人々を問題に投げかけてしまっています。
スケーラビリティとは「自動化」に要約されます。数十のフットプリントから数百または数千のフットプリントへの移行方法はどのように変わるべきでしょうか?それは自動化しましょう、という言葉に要約されるのです。
リソース管理、セルフサービスプロビジョニング、およびその他の領域もスケーラビリティに重要です。インフラストラクチャの所有権をチームに戻すことで、チームがワークスペースを可視化し、運用チームにリクエストを発するだけでなく、自分のリソースをより効果的に割り当てて管理できるようになるからです。Fong-Jones氏によれば所有権を戻し自己統制を進めるには、プロセスとツールの標準化が必要だとも述べています。
「1つのSREチームは、それぞれが独自の作業を行っており、それぞれが別々のツールを使用していることがあります。しかし50の異なるソフトウェアエンジニアリングチームを的確にサポートするのは非常に困難です。できる限り多くの製品開発ソフトウェアエンジニアリングの同僚に対応できるようにするためのベストプラクティスを公式化しました。」
2.SREを成功させるもの
SREの技術的貢献は、特定の組織がSREの役割をどのように定義またはアプローチするかに依存しています。ある会社はより多くのソフトウェアエンジニアリングとコーディングの経験を必要とし、別の会社は運用またはQuality Assuarance スキルにより高い価値を置く可能性があります。バランスがどうであれ「必要充分な」から「卓越した」というスキルレベルを区別するには、多くの場合技術的な専門知識を補完する習慣と特性の組み合わせによって実現されています。
SREは大きな視点で物事を捉える
成功したソフトウェア開発者は、コードがビジネス全体の推進にどのように役立つかを理解しています。優れたSREもこの特性を備えています。成功するSREは、物事をより高いレベルで理解および解釈できる人です。なにがしかの変更は、その瞬間だけでなく将来のリスクや影響を引き起こす可能性があり、優れたSREはその変更を行う前に徹底的な分析を確実に実行します。
特定のシステム、チーム、または大規模なインフラストラクチャにSREの作業がどのように影響するかを考える能力は、SREとしての実用主義を表現することと同義です。ステークホルダーにどのような影響を与えるかを考えず壁を越えて変化をもたらそうとする、サイロ化されたアプローチには長期的な利点はほとんどないと言っていいでしょう。
SREはあらゆるシーンで自動化の機会を狙う
優れたSREは、企業がソフトウェアを迅速にデリバリする能力を低下させることなく、あらゆるものの信頼性を向上させることに成功しています。そして、それらは「自動化」によって実現しています。優れたSREは、苦痛を伴う手動タスクと労力を自動化することについて積極的に取り組んでいるのです。人々がしている非効率的で時間のかかることを発見し見つめ直し、今すぐこれを自動化して他の誰かがこの苦痛な作業を続けることを止める、それも SRE の役割です。
この自動化へのこだわりは、SRE(およびDevOps)哲学の重要な教義です。実際、DevOpsハンドブックには、手動承認プロセスの直感に反する影響について説明する章があります。「自動化、自動化、自動化、さらに…自動化!」がSREの求人リストの主要な責務であることは、予想外のことではありません。
SREは新しいツールとアプローチを採用する
SREはまだかなり新しいため、現在 SRE の肩書きを保持している多くのエンジニアは、他の職務に従事していたことがほとんどです。開発者のバックグラウンドを持つSREもあれば、運用バックグラウンドをもつSREである場合もあります。SREの役割を特定のバックグラウンドに限定しないことが重要です。たとえば、従来のQuality Assuarance エンジニアは、SREポジションに適したスキルや経験を持っているかもしれません。
ただし、あなたの経歴に関係なくSREの役割は快適なゾーンから出て新しいスキルを開発するような挑戦に取り組む姿勢が必要です。たとえば、運用の実践者はプログラミング言語を学習することで恩恵を受ける場合がありますが、開発の経験がある人は、運用プロセスと過去の課題をより深く考えることができるはずです。最高のSREは広範な学習とスキル開発を取り入れています。
SREはチェンジ・エージェントになる
偉大なSREは、やりたくないことを他の人に説得しやってもらう、ということが含まれます。たとえば、ソフトウェアエンジニアには今後数年間にわたって機能を拡張する方法を検討するよう説得します。また、優れたSREは「掘り下げましょう」「やめましょう」と「いいえ」を”声に出して発言できるよう”にする必要があります。これは一部のエンジニアリング組織では困難な場合があります。またSREは、意図はあるが生産的ではないプロセス、手順、ツールを喜んでダンプすることができる必要があります。
3. SREツールとプロセス
SREに普遍的な職務記述書がないように、この役割にも標準的なツールセットはありません。ただし、優れたSREは常に信頼性を得るためのツールとプロセスを最適化し、組織全体でそれらを広めることを目指しています。最適化はSREプラクティスを成功させ、DevOps原則を適切に実装するための鍵です。しかし、SREはどのツールを標準化する必要があるでしょうか。
DevOps(およびSRE)ツールチェーンの段階
「SREツールチェーンのステージ」を考えた場合、SRE は実際にはDevOpsを最も純粋な形式で表現しているという信念があっても驚くことはないでしょう。
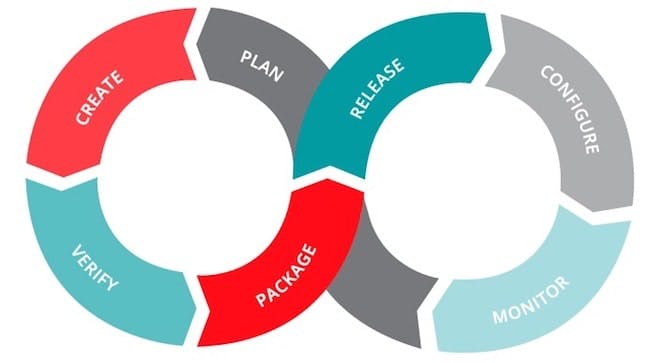
New Relicでは、SREがますます重要な役割を果たし、従来の開発チームと運用チームでかつてサイロ化されていた責任を結合しています。その結果、「DevOpsツールチェーン」と「SREツールチェーン」の間に大きな違いはあまりないと考えています。いくつかのフェーズでどのようなツールを使うのかを記載してみます。
計画: JIRAや Pivotal Trackerなどのアジャイルプロジェクト管理および追跡ツール、またはその他のタスク管理ツール。
開発:統合開発環境(IDE)、テキストエディター、および共有ライブラリとコンポーネントなど実際にアプリケーションを構築するために使用するビルディングブロック。ここでもSREには大事な役割があります。たとえば信頼性の高いコードまたはサードパーティのライブラリを再利用するために、すべてをゼロから構築することを避けるように開発チームを奨励します。GitHubやSubversionなどのソース管理ツールは、devロールとopsロールの境界を消去し、展開環境とプロセスの管理を担当するSREの間で非常に人気があります。
確認: Jenkinsや CircleCIなどのビルドおよび継続的統合/継続的配信(CI / CD)ツール。
パッケージ: Rakeや JFrogなどの本番対応ソフトウェアのビルド、パッケージング、リリースステージング、および承認プロセスを管理するツール。
リリース: Apache Mavenや XebiaLabsなど、アプリケーションのリリースとライフサイクルを管理するツール。
構成: Terraformや Ansibleなどのツールは「自動化!自動化!そして自動化!」のSRE哲学に適合し、チームがインフラストラクチャおよびアプリケーション全体の構成を自動化および管理できるようにします。SREはそれらの構成が正常性と信頼性の観点からどのように見えるかを決定する際に重要な役割を果たします。これらのツールは、必要なルールとプロセスを実装するためにこれまで必要だった手動作業の多くを自動化するのにも役立ちます。
コンテナの使用が増えると、多くの組織でこれらツールの必要性が最終的に減少する可能性があることにも注目しましょう。コンテナ化されたアプリケーションには、すべての依存関係と構成が不変の構成で含まれているため、Dockerなどのコンテナープラットフォームや、KubernetesやMesosphereなどのオーケストレーションサービスがSREに不可欠になりつつあります
監視:監視は多くの人にとって多くのことを意味しますが、何らかの形式のログまたは分析データでアプリケーションおよびインフラストラクチャからメトリクスを収集し、構成可能なダッシュボードを介してそのデータに関するアラートを収集する場合は、 New Relicのようなツールも含まれています。
SLOとSLIを使用して信頼性を測定する
サービスレベル目標(SLO: Service Level Objective)は、サービスプロバイダーのパフォーマンスを測定する一般的な方法であり、SREの成功にとって同様に重要です。製品およびサービスレベルで明確に定義および測定されたSLOメトリクスは組織が以下を行うのに役立ちます。
- 投資とその優先順位付けを行い、信頼性の目標を達成し、企業の戦略に合わせて高レベルの信頼性目標を有意に調整します。
- 顧客の信頼を維持、または構築します。
- 信頼性に重点を置く時期と方法を決定します。
- エンジニアがリスク許容度についてより良い仮定を立てるのに役立つだけでなく、依存関係をよりよく推論して不必要な労力を減らします。
チームが常にSLOを超えている場合(たとえば、すべてのサービスの可用性が99.9%)、チームはより機敏に活動し、より多くのリスクを負うことができます。チームがリスクにさらされている場合、またはSLOを満たしていない場合は、チームが再び速く動き始めることができるように一時停止して信頼性に集中することを示すシグナルと捉えることができます。
サービスレベルインジケータ(SLI: Service Level Indicator)を使用して、信頼性を測定することも大事です。これらのパフォーマンスメトリックは、ビジネスの一部を追跡します。たとえば、データベースサービスのSLIは、「エラーなしで200ミリ秒以内に正常に完了したユーザークエリの割合」のようになります。
信頼性を測定するために、チームは平均故障間隔(MTBF: Mean Time Between Failure)、平均修復時間(MTTR: Mea Time To Resolution)、平均検出時間(MTTD: Mean Time To Detection)などのメトリクスに頼ります。これらはすべて、組織の「リスクマトリクス」を定義することに役立ちます。これらは強力なツールになります。 SLOに対して「定量化可能な影響を与える問題とリスク」に優先順位を付けていくことが可能になるからです。
SREが常に使用するツールは、組織がSREの旅のどこにいるかによって異なります。成熟度の低い組織では、より専門的な運用ツールを使用する傾向があり、成熟度の高い組織では、SREとソフトウェアエンジニアリングツールチェーンの間の収束性が高まります。そのため万能なツールセットがないことは確かですが、SREはすべての作業に高い信頼性をもたらす新しい効率的な方法を模索しながら、適切なツールを試して採用する必要があります。
4.New Relic における SRE の役割
Googleのサイト信頼性エンジニアリングの書籍は、DevOpsの世界で最新のSREプラクティスがどのようにあるべきかを概説する素晴らしい仕事をしています。しかし、Googleほどの規模ではない企業でのSREプラクティスはどうでしょうか?SREが他のエンジニアリング組織で果たす日常的な役割の具体的で詳細な説明を見つけることは驚くほど困難です。インターネット上のほとんどの説明には、「SREはソフトウェアエンジニアリングと運用スキルセットを組み合わせたもの」や「SREはすべてを自動化したもの」などの比較的曖昧なフレーズが含まれています。
Matthew Flamingは、New RelicがSREの役割をどのように定義するかについて多くの考えを入れ、潜在的な候補者から経営幹部まで、すべての利害関係者が彼らのSREに期待するものを正確に理解できるようにしました。
役割を定義する
New Relic の SREは、個々のSREと経営陣のリーダーシップからのインプットが含まれています。Flamingによると、SREは価値のある投資であると判断しています。
- New RelicでSREが重要な理由。
- SREチームのビジョン。
- SREがNew Relicプラットフォームの将来に最も効果的に貢献する方法。
New Relic の SREはシステムの信頼性の向上に重点を置いているエンジニアです。ビジネスの観点から見ると、SREが行う作業の目標は顧客の信頼を構築および維持し、New Relicのプラットフォームのサービスごと、およびホストごとの運用オーバーヘッドを着実に削減することでビジネスを拡大できるようにすることです。
高レベルでは、SREはこれを次の方法で実現します。
- 信頼性ベストプラクティスを実践し支援する。
- レジリエンスと低労力を考慮した設計とプロセスをガイドする。
- 技術的な複雑さとスプロールを減らす。
- ツールと共通コンポーネントの使用を促進する。
- 弾力性を向上させ、運用を自動化するためのソフトウェアとツールを実装する。
SREをセットアップして成功に導く
上述のようなSREの役割はNew Relicでうまく機能しますが、他の組織には適切でない場合があります。とにかく有用な例を提供し、優れたSREプラクティスがもたらす可能性のある大きな価値を明確にすることには役立つでしょう。独自のガイドラインを作成することによりSREを成功に導き、SREプラクティスが成熟するにつれてSREガ果たす重要な役割の集合的理解を深め、ますます複雑化するコンピューティングプラットフォームの信頼性獲得を支援していきましょう。
最後のメッセージとしては、SREは信頼性に深く関心を持ち、ベストプラクティスを相互に共有する他の人々のために、実践のコミュニティとメンター/メンティーの関係を構築することが重要です。
最後に
SREの役割を定義し、適切な組織構造とインセンティブを設定したら、あとはすべて実践に委ねられます。成功するSREチームは、さまざまなスキルと特性に依存しています。いつでも技術的なスキルを教えることができますが、必ずしも共感や好奇心などの本質的な資質を伝えることはできません。
New Relicのようなエンジニアリングカルチャーは自主性を賞賛しますが、それはチームが独自に信頼性に取り組む必要があるという意味ではありません。チーム(および個々のSRE)が成功するには、組織のサポート、コミュニケーション、そして何よりも信頼を獲得することが必要です。
成功したSREの指針となる哲学は次のように表現できます。
”物事が壊れることを防ぐことはできません。その代わりに、全体像を把握し、自動化を取り入れ、健全なパターンを奨励し、新しいスキルとツールを学び、あなたが行うすべての信頼性を向上させるために、たゆまぬ努力をしてください。完璧さは達成不可能かもしれませんが、常により良いことをしようと努力することは、可能な限り完璧に近づくことを可能します。”
New Relic について聞きたいことがある時はこちらまで。
![]()

本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


