New Relicの信頼性エンジニア Beth Adele Long によるブログ記事 “On-Call and Incident Response: Lessons for Success, the New Relic Way” の翻訳です。オリジナルの記事は今から1年半ほど前、2018年10月に公開されたものです。
(このポストは2018年2月13日に投稿されたポストを参考に構成されています)
とんでもなく多くの企業がオンコールのローテーションやインシデント対応プロセスを採用しており、チームメンバーは不安やストレスに晒され、悲壮感に包まれます。注目すべきは、優秀なエンジニアの多くが、この理由で仕事を辞退していることでしょう。
そんな心配はもう必要ありません。New Relicでは、DevOpsを実践し、オンコールとインシデント対応のプロセスを構築することで、急速な成長をサポートしつつシステムの信頼性を最大化することができました。オンコールローテーションやインシデント対応システムを構築・管理した経験とベストプラクティスを共有することで、他の企業が同様の課題を解決し、自社の開発者や他の実務者がより楽に生活できるようになることを願っています。
New Relicからの学ぶ、実践オンコールポリシー
New Relicのプロダクトチームは現在、400人以上のエンジニアとマネージャーからなる50以上のエンジニアリングチームで構成されており、200以上のサービスをサポートしています。各チームは独自の自律的なユニットであり、使用するテクノロジーを選択し、独自のサービスを書いて保守し、独自のデプロイメント、手順書、そしてオンコールローテーションを管理しています。
New Relicのエンジニアリングチームは、ソフトウェアエンジニア、サイト信頼性エンジニア(SRE)、エンジニアリングマネージャーで構成されています。ほとんどのチームは、少なくとも3つのサービスを担当しています。また、組織内のすべてのエンジニアとエンジニアリングマネージャーは通常、入社後2~3ヶ月以内にオンコールのローテーションに参加します。
私たちがこれを行う理由は、何よりもまず第一に必要だからです。New Relicは、世界中の何千ものお客様に対して、アプリケーションやインフラストラクチャの重要な監視、アラート、ビジネスインテリジェンスを提供しています。お客様に問題が発生した場合、翌日まで問題を放置しておくことはできません。New Relicは米国とヨーロッパにエンジニアを配置していますが、ほとんどのチームはオレゴン州ポートランドにあるグローバルエンジニアリング本部で作業しています。つまり、Google のような、ある地域のエンジニアから地球上の別の地域の仲間に譲る「フォロー・ザ・サン」ローテーションは不可能だということになります。
ベストプラクティス: DevOpsプラクティスを採用し、浸透させる
アプリケーション開発の方法論として DevOps が登場する前は、オンコールの職務は通常、中央集権的なSREチームや運用チームのような、一部のエンジニアやIT担当者に依存していました。
これらのスタッフは、実際にソフトウェアを構築した開発者ではないにも関わらず、自分たちが監視しているサービスに関わるインシデントに対応していました。残念ながら、サイト信頼性チームからのフィードバックが開発者に届くことはほとんどありませんでした。さらに、プロダクトオーナーは、技術的な負債を返済したり、製品やサービスの信頼性の高めたりせずに、新機能の開発を優先する、そんなことがよくありました。
DevOps誕生 の理由の一つは、このような組織的なサイロを解体することでした。New Relicが採用しているようなモダンなアプリケーションアーキテクチャでは、サービスとは、大規模で相互に接続された製品プラットフォームで構成されており、クラウドサービスやデータベース、そしてネットワークレイヤーが入り組んだ、複雑なシステムになります。特定のインシデントへの対応は1つのチームから始まるかもしれませんが、根本的な原因はスタックのさらに下にあるサービスにあるかもしれません。
DevOpsでは、次のようなアイデアを持っています -- 「どのチームも孤立した存在ではなく、チームは相互作用する」。そんな複雑なシステムをスムーズに稼働させるためには、明確で、文書化されたオンコールプロセスを持たなければならない。さらに、DevOpsの重要なプラクティスに「開発者は、自分たちが構築したサービスをサポートしなければならないとしたら、そのサービスについてより良い判断を下すことができる」というものがあります。壁の向こうにいる人達にサービスをぶん投げてあとは知らない、ということはできません。
ベストプラクティス: 自主性を持ちつつ説明責任を果たす
ほとんどのNew Relicのチームでは、1週間のオンコールローテーションを採用しており、1人のエンジニアをプライマリレスポンダー、もう1人のエンジニアをセカンダリレスポンダーとしています。つまり、チームに6人のエンジニアがいる場合、それぞれのエンジニアは6週間ごとにプライマリレスポンダーとしてオンコールを行います。
しかし、オンコールプロセスを成功させるかどうかは、チームの構成、管理するサービス、さらにサービスに関するチームの総合的な知識にかかっています。ここでチームの自律性が登場します。New Relicでは、それぞれのニーズと能力を反映した、各チーム独自のオンコールシステムを作っています。
さて、このアプローチがどのように実践されているのか、2つの例を紹介しましょう。
New Relic metricsのパイプラインチームは、常に「プライマリ」と「非プライマリ」のオンコールコンタクトが存在するように、ローテーションを構成しています。Jenkinsでスクリプトを実行し、チームは非プライマリのオンコールの順番をランダムにローテーションしています。インシデントが発生したときに、プライマリの連絡先が利用できなかったり、応答しなかったりすると、プライマリ以外の連絡先がランダムな順番でコールされ、誰かが応答するまで続きます。
New Relic Browserチームでは、設定可能なカスタムアプリケーションを使用しており、1分毎に、別のチームメンバーを「プライマリ」にするようローテーションさせています。チームメンバーがコールにすぐに応答しない場合は次の人に交代され、その人が応答しない場合はさらに次の人に…、アラートに応答する人が現れるまで続けられます。このアプローチは、実際にチームメンバーのプレッシャーを軽減します。インシデントが発生しても、対応できなかったり問題に対処する準備ができていない場合は、2分後には別のチームメンバーに引き継がれるようになります。
ベストプラクティス: オンコールのパフォーマンスを追跡・計測する
New Relicでは、エンジニア個人、チーム、グループレベルでオンコールのメトリクスを追跡しています。
- エンジニア1人あたりのオンコール受信数
- エンジニアがオンコール対応した時間数
- 通常の営業時間外に発生したオンコール受信数
チームがオンコールの実践を成功させ、組織形態を運営していくために、これらのメトリクスをどのように活用するかが非常に重要になります。例えばNew Relicでは、PagerDutyを使ってアラートデータを管理し、ある時間枠の中でチームが何回コールされたか、アラートのうち何回が時間外に発生したか、マネージャーや役員が管理できるようにしています。
時間外のコールをトラッキングすることで、管理不可能なオンコールの負荷に悩むチームに注意を向けることができます。管理不可能とはどういう状態でしょうか?New Relicでは、あるチームに週平均1時間以上の時間外コールが起こった場合、そのチームはオンコールの負荷が高いと考えられています。
チームの負担が大きすぎる場合、オンコールの負担が軽減されるまでの間、技術的な負債を返済することに専念したり、作業を自動化したりすることを検討します。もしくは、New Relicでは、サイト信頼性エンジニア(SREs)がチームを支援して、サービス改善をサポートすることもやっています。
オンコールモデルを選択する際に考慮すべき事項
オンコールモデルは複雑であるべきではありません。しかし、エンジニアが常にコールに対応でき、その責任範囲に関わるインシデントに対処できるようにしなければなりません。オンコールモデルが考慮すべき事項は、次のようなものです。
- モデルはどのようにして、各オンコールローテーションでチームメンバーを選択するのか?
- 1つのローテーションはどのくらい続くのか?
- オンコールのエンジニアが応答しなかった場合にどうするか?
- オンコールのエンジニアが応答できたが対応が難しい場合に、どのような選択肢があるか?
- 常時、何人のエンジニアが待機しているか?
- オンコールのエンジニアが複数いる場合、どのように職務を分担するか?
- 予定外のローテーション、その他の不測の事態に、チームはどのように対処するか?
複数のチームを持つ大規模な組織の場合、その答えはチームの自律性の度合いにも依存します。DevOpsが進んだ組織では一般的に、高いレベルのチームの自律性を重視しています。中には、このコンセプトを他の組織よりも先取りしている組織もあります。
インシデント対応: オンコール担当者がいなくなると何が起こるのか
組織のオンコールプロセスは、組織のソフトウェア品質と信頼エンジニアリングを実践する上で、重要な側面を担います。もう一つの密に関連した側面として、インシデント対応手順があります。
インシデント対応は、平凡なものから恐ろしいものまで、幅広くカバーしています。中には、特殊な監視ツールの助けを借りなければ気づくことができないものもありますし、何百万人ものユーザーに影響を与え、全国的なニュースになる可能性のあるものもあります。
New Relicにおける「インシデント」とは、「システムが予想外の振る舞いをして、顧客に悪影響を及ぼす可能性がある事象」と定義しています。
New Relicでは多くのソフトウェア企業と同様に、インシデントが発生してから計画を練るような余裕はありません。迅速かつ効率的に行動する必要があります。事前に明確なプランを立てて、すぐに実行できるようにしておかなければなりません。
ベストプラクティス: 顧客よりも先にインシデントを発見する
インシデント対応システムを成功させるための目標はシンプルです。インシデントを発見し、可能であれば、顧客が影響を受ける前に修正することです。
組織としての私たちの目標は、イライラしているお客様のツイートでインシデントを発見するようなことをなくすることです。これは最悪のケースの一つでしょう。もしくは、怒ったお客様がサポートに電話をかけてくることもないようにしたいものです。どちらも、理想的なシナリオとは言えません。
New Relicでは、「自分たちのシャンパンを飲む」と言っています(「自分たちもドッグフードを食べる」よりも良くないですか??)。エンジニアリングチームは、サービスを構築するために使用する技術を自由に選択することができますが、1つだけ条件があります。サービスは計装されていなければなりません。言い換えると、モニタリングとアラート機能がなければならないということです。レアケースを除けば、New Relicは自社製品を使用しています。
もちろん、上述したように、エンジニアリングチームは自分たちが管理するサービスのために、オンコールローテーションを行っています。プロアクティブ(能動的)なインシデントレポートを備えた優れたモニタリングを用いて、問題が検出されるとすぐにエンジニアに通知され、上手くいけば、顧客が気付く前にチームが気付くことができます。
ベストプラクティス: インシデントの深刻度を評価するシステムを開発する
効果的なインシデント対応は、インシデントの深刻度(一般的には、顧客への影響度)に基づいてインシデントをランク付けするシステムから始めてみましょう。New Relic内部ではインシデントの重大度スケールを管理しており、組織に合ったインシデント対応プロセスを構築する上でスタート地点として活用しています。
- Level 5: 顧客に影響はないが、危険なデプロイに対する警告など、何かに対する意識を高めるためだけに宣言される
- Level 4: 顧客に影響はあるが支障はない、軽微なバグやデータ遅延など
- Level 3: 重大なデータ遅延や機能不全など
- Level 2 および Level 1: 短期間の全製品の停止など、ビジネスの脅威に直結するもの。New Relicでは、数年前に発生した「Kafkapocalypse」がこのレベルの一例です。
インシデントレベルでそれぞれ、社内リソースの呼び出し、対応の管理、顧客とのコミュニケーションの必要性とそのやり方、その他のタスクなど、具体的なプロトコルが定められています。New Relicでは、最も深刻なインシデントを「エマージェンシー」としてクラス分けしています。これらのインシデントには通常、高度な対応が必要とされ、場合によっては法務、サポート、リーダーシップチームによって直接関与されます。
インシデントが顧客にどのような影響を及ぼし、顧客体験にどのようなインパクトを与えるかを検討することは非常に重要です。そして、対応チームのリソースを考慮しながら、問題を診断し、封じ込め、解決するのです。
New Relicでは、インシデント発生時に深刻度レベルを設定し、どの程度のサポートが必要かを判断しています。そして、インシデント発生後には、実際のお客様への影響度に基づいて、割り当てられた深刻度レベルを再評価します。ここに、New Relicの重要なインシデント対応の原則が現れています。インシデント発生時には、エンジニアが問題解決に必要なサポートを受けられるように、迅速にエスカレーションを行うことを推奨しています。インシデント対応が終了した後、実際の影響度を評価し、当初恐れていたほどではないことが判明した場合には、深刻度を引き下げます。
ベストプラクティス: 対応チームのロールを定義し、アサインする
以下の表は、New Relic がインシデント対応チームのスタッフとして使用している役割の概要を示しています。これらの役割の多くで、特定の深刻度レベルで設定されています。また、インシデントの深刻度に応じて、役割に割り当てられる責務が変わる場合もあります。
| ロール | 説明 | 対応組織 |
|---|---|---|
| インシデントコマンダー (IC) | サイトのインシデントの解決を推進する。インシデントの影響と解決状況を CL に通知する。新たな合併症が発生しないように注意を払う。
ICは、インシデントの技術的診断は行わない。 |
エンジニアリングチーム |
| テックリード (TL) | インシデントの技術的診断と修正を行う。技術的な進捗状況をICに通知する。 | エンジニアリングチーム |
| コミュニケーションリード(CL) | インシデントが発生した際に、顧客への影響レポートをICに通知する。顧客とビジネスに対してインシデントについての情報を提供し続ける。提供に使う通信チャネルを決定する。 | サポートチーム |
| コミュニケーションマネージャ (CM) | 社内チーム間の緊急コミュニケーション戦略の調整する。カスタマーサクセス、マーケティング、法務など。 | サポートチーム |
| インシデントリエゾン (IL) | サポートとビジネスに情報を提供し、IC が解決に集中できるようにする。
深刻度 1 のインシデントのみで登場する。 |
エンジニアリングチーム |
| エマージェンシーコマンダー (EC) | 複数の製品がダウンした場合に「ICのIC」として振る舞う。
深刻度 1 のインシデントで、必要に応じて登場する。 |
エンジニアリングチーム |
| エンジニアリングマネージャー (EM) | インシデントの根本原因と結果に応じて、影響を受けたチームのインシデント後のプロセスを管理する。 | エンジニアリングチーム |
ベストプラクティス: インシデント対応シナリオを用意する
ほとんどの組織では、実際のインシデント対応、特に高難易度のインシデントを完全にシミュレートすることはできません。しかし、限定的なシミュレーションを使って、インシデント中に何が起こるか、優先順位やエスカレーション手順の設定方法、チームの役割の調整方法など、重要な洞察を得ることができます。
例を見てみましょう。New Relicでの仮のインシデントです:
このシミュレーションは、New Relicのプロダクトチームのオンコールエンジニアがコールを受けるところから始まります。このエンジニアのサービスのヘルスチェックを監視しているNew Relic Syntheticsのミニオンが、ヘルスチェックに失敗していることを知らせてきました。彼女はそのサービスの New Relic Insights ダッシュボードをチェックしてみると、確かに、ヘルスチェックが失敗しており、スループットが低下していることがわかりました。そうなると、顧客が困っていないか心配になってきます。これから何が起こるのでしょうか?彼女は何をすべきなのでしょうか?
まず最初に、彼女は指定されたSlackチャンネルでインシデントを宣言します。Nrrdbot(GitHubのHubot を改造したもの)と呼ばれるボットが、そこからのプロセスをガイドします。彼女はインシデント・コマンダー (IC)の役割を担うことにしたので、「911 ic me」と入力します。これによりSlackのチャンネルヘッダーが更新され、Upboard(社内の自作インシデントトラッカー)に新しいオープンなインシデントが作成されます。そして、Nrrdbotは次のステップを知らせるダイレクトメッセージをエンジニアに送ります。
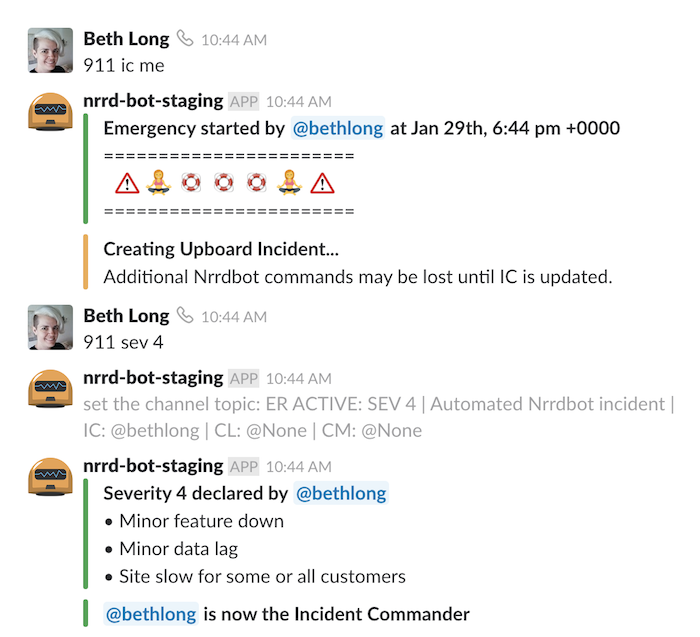
ICがすべきことは3つあります:
- 深刻度(どのくらい悪い状況か)を設定する。
- インシデントのタイトル(何が問題なのかの要約)とステータス(現在進行中の状況の要約)を設定する。
- 問題をデバッグするためのテックリードを1人以上見つける。ICがテックリードに最適な人であれば、ICの役割を引き継ぐ人を探す(ICはインシデントの技術的な診断を行わない)。
ICが深刻度を設定(もしくは対応中に深刻度を変更)すると、誰が対応を支援するために参加するかが決定されます。Level 3のインシデントでは自動的に、サポートからのチームメンバーがコミュニケーションリード (CL) としてインシデントにアサインされます。顧客とのコミュニケーションを調整して、インシデントに関連する顧客からの苦情を受け付けたり、エンジニアの状況に基づいて顧客と積極的にコミュニケーションを取るのがCLの仕事です。
この時点で、ICは全員で読み書きできる連絡文書を用意し、対応に参加している全員の間で共有します。対応に関わるすべての関係者間のコミュニケーションの流れを管理するのが、ICの仕事です。また、必要に応じてサポートチームを組織して、状況を更新しながら(10分ごとに、Nrrdbotが通知してくれます)、状況が良くなったり悪くなったりした場合には深刻度をアップデートします。
60分から90分以内に問題が解決しない場合は、ICの役割を他の人に譲ります。とくに午前3時に熟睡から起こされたときは大変ですよね。
問題が完全に解決され、すべてのリードが問題ないことを確認したら、ICはSlackで「911 over」と入力してインシデントの終了を宣言します。これで対応は完了です。
ベストプラクティス: 最善を望み、最悪に備える
上の例では、New Relic 社の重大なインシデントをシミュレートしていますが、真のエマージェンシーレベルには達する事故ではありませんでした。エマージェンシーが発生することは非常に稀ですが(もちろんそうあるべきだと思います)、ビジネスにとっては指数関数的に高いレベルのリスクをもたらします。実際、真の最悪のケースでは、インシデントが制御不能な状態に陥り、実存的な脅威に変わる可能性があります。
New Relicでは、Level 1またはLevel 2の深刻度のインシデントが発生すると、自動的にバックグラウンドプロセスが開始され、New Relic Emergency Response Force (NERF) のメンバーとオンコールエンジニアリング担当役員に連絡が入ります。NERFのチームメンバーは、New Relicのシステムやアーキテクチャ、およびインシデント管理プロセスを深く理解している経験豊富なNew Relicの社員です。彼らは、特に複数のチームの調整が必要とされるような高難易度のインシデントへの対応に長けています。
オンコールエンジニアリング担当役員はNERFのインシデント対応チームに参加し、経営陣への情報提供、法務・サポート・セキュリティチームとの調整、厳しい決断を下すという3つの重要な機能を担います。
ベストプラクティス: インシデントによって学び、改善し、成長する
インシデントから知識を得て学習するための最初のステップとして、私たちの例のNew RelicのICは、インシデント後にいくつかのタスクも実行します。
- 最終的な詳細をまとめ、連絡文書に以下の事項を残す
- インシデントの期間
- 顧客への影響
- あとでロールバックする必要がある緊急の修正
- インシデント中に生じた重要な課題
- インシデント対応のふりかえりに誰が参加すべきか
- 非難なしのふりかえりに、誰を招待べきか確認する
- インシデントを所有するチーム(上記の例では、Syntheticsチーム)を指定して、そのチームのエンジニアリングマネージャーがインシデント対応のふりかえりのスケジュールを設定させる
また、インシデント発生後1~2営業日以内にふりかえりを実施することをチームに義務付けています。New Relicでは、「非難なしの」ふりかえりを実施して、スケープゴートを見つけることなしに、問題の根本原因を明らかにしています。New Relicが非難なしのふりかえりをどのように設定して活用しているか、 DevOps Done Right もご覧ください。
ベストプラクティス: Don’t Repert Incidents (DRI) を実施する
New Relicでは、サービスインシデントがお客様に影響を与えた場合、 Don’t Repeat Incidents (DRI) ポリシーを定めており、インシデントの根本原因を解決するか緩和するまでは、そのサービスの新規作業を中止することを義務づけています。DRIプロセスは、New Relicのエンジニアリングチームの成功に大きな役割を果たしており、他の方法では優先順位が付けられない作業である技術的な負債を特定して返済することを保証しています。
常に意識してほしいのは、インシデントを完全になくすことが目標ではないということです。その代わりにNew Relicでは、将来発生したインシデントに対してチームがより効果的に対応できるようにしたいと考えています。
次はあなたのターンです:インシデント対応計画を作るときの確認事項
これまで、New Relicがオンコールやインシデント対応プロセスをどのように処理しているのか、また、私たちの経験から得られるベストプラクティスをご提案してきました。私たちがおすすめするのは、明確なガイドラインを作成して、チームに何を期待しているか理解してもらうことです。そうすることで、チームがインシデント対応や解決プロセスにおける最悪な軋轢を特定して軽減し、オンコールやインシデント対応プロセスをどのように構成するかを具体的に決定することができるようになります。
以下の質問に対処することで、これらのタスクをより効率的に実行することができます。
- 規模: エンジニアリング組織の規模は?個々のチームの規模は?チームはどのようなローテーションで対応できますか?
- 成長の速さ: エンジニアリング組織の成長速度は?離職率は?
- 地理的要因: あなたの組織は地理的に集中していますか、それとも広く分散していますか?それとも、エンジニアが時間外のコールに対応する必要がありますか?
- 組織: エンジニアリング組織はどのように構成されていますか?開発から運用までサービスのライフサイクル全体をチームが所有するという、モダンなDevOps文化を採用していますか、それとも開発と運用がサイロ化されていますか?SREは中央集権的か、もしくは組織を横断してエンジニアリングチームに組み込まれていますか?
- 複雑さ: アプリケーションはどのように構成されていますか? あなたのエンジニアは、より大きなアーキテクチャに接続された明確に定義されたサービスをサポートしていますか?各チームはどのくらいのサービスをサポートしていますか?それらのサービスはどれくらい安定していますか?
- 依存関係: サービスに依存している顧客(内部または外部)の数は?サービスにインシデントが発生した場合、爆発半径はどのくらいですか?
- ツール: インシデント対応プロセスとツールはどの程度洗練されていますか?チームの手順書やモニタリングはどれくらい徹底していますか?エンジニアがコールに対応する際に、適切なツールや組織的なサポートを受けていますか?エンジニアは実用的な通知を自動で受けていますか?
- 期待すること: あなたの会社のエンジニアリング文化では、オンコールが当たり前になっていますか?オンコールは仕事の貴重で不可欠な部分とみなされていますか、それとも余計な負担とみなされていますか?
- 文化: あなたの会社には、誰かを非難することなく、真の根本原因を見つけ、システム上の問題に対処することに焦点を当てる文化がありますか?それとも、何か問題が起きたときに人々が罰せられる「非難と恥」の文化ですか?
本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


