自分たちのシステムにオブザーバビリティ(可観測性)を得てビジネスの成功につなげるためにはまず何が必要なのでしょうか。それにはSLOが必要だという「Why SLOs Are Essential for Observability」を抄訳にてお届けします。
従来の監視の世界では、監視しやすいから、あるいは可用性やパフォーマンスと単純には相関しているから、といった理由でリソースの消費量(CPU、ディスク、メモリなど)をまず監視していました。私のように継続的な改善に取り組んでいた場合、すぐに膨大な数の細かいリソースメトリクスを収集することになり、それらを理解するために迷路のような相関ルールを維持する必要がありました。
しかし、DevOpsとオブザーバビリティ(可観測性)の世界にいる今、あなたにはそれ以上のものが必要です。その理由は以下の通りです。
- クラウド環境では、リソースの消費量を測定できない(あるいは測定すべきでない)ことがあります。
- ワークロードの変動が激しく、閾値の設定が難しい場合があります。
- 何を測定するかについての柔軟性と、測定方法のコントロールが必要です。
- 様々な人に素早く簡潔にステータスを伝える必要があります。
最も重要なことは、IT環境が拡大していることです(マイクロサービスを考えてみてください)。そのため、収集するものを簡素化し、より適切なものにする必要があります。そうしないと、保存したメトリクスは馬鹿げたほど膨大になり、付加価値のない管理作業を増やすばかりです。
スピードと品質を測定することで、これまでとは異なるアプローチをとる
あなたの顧客(社内外問わず)は、迅速で高品質な応答を提供するテクノロジーを期待していますが、細かいことは気にしません。お客様の期待に応えようとするならば、レスポンスタイム(スピード)とエラー(品質)の測定に重点を置くべきです。さらに、すべてを1つのわかりやすい数字に集約する必要があります。これにより、運用チームやエンジニアリングチームがどこに注意を向けるべきかがわかり、技術者ではないステークホルダーが現在の状況を直感的に理解し、ビジネス上の重要な意思決定を行うことができます。
これは重要なことです。ビジネスでは、あるプロセスが以前よりも2%多くCPUを消費していることは気にすることはなく、顧客体験を気にしているからです。つまり、スピードと品質という2つの重要なポイントを測定し、伝達することが必要です。
ここで、サービスレベル指標(SLI)とサービスレベル目標(SLO)が助けになります。両者を使ってビジネスの期待に応えるには、まず技術者と非技術者の両方のステークホルダーが理解できるSLI指標を特定します。そして、スピードと品質の義務をどのくらいの頻度で果たしているかを示す、単純なパーセンテージの形で目標(SLO)を設定します。
例として、私のお客様のB2B-Gatewayというマイクロサービスの一つのデータを紹介します。彼らはこのように、時間経過に伴うエラーの量のデータを収集しています。
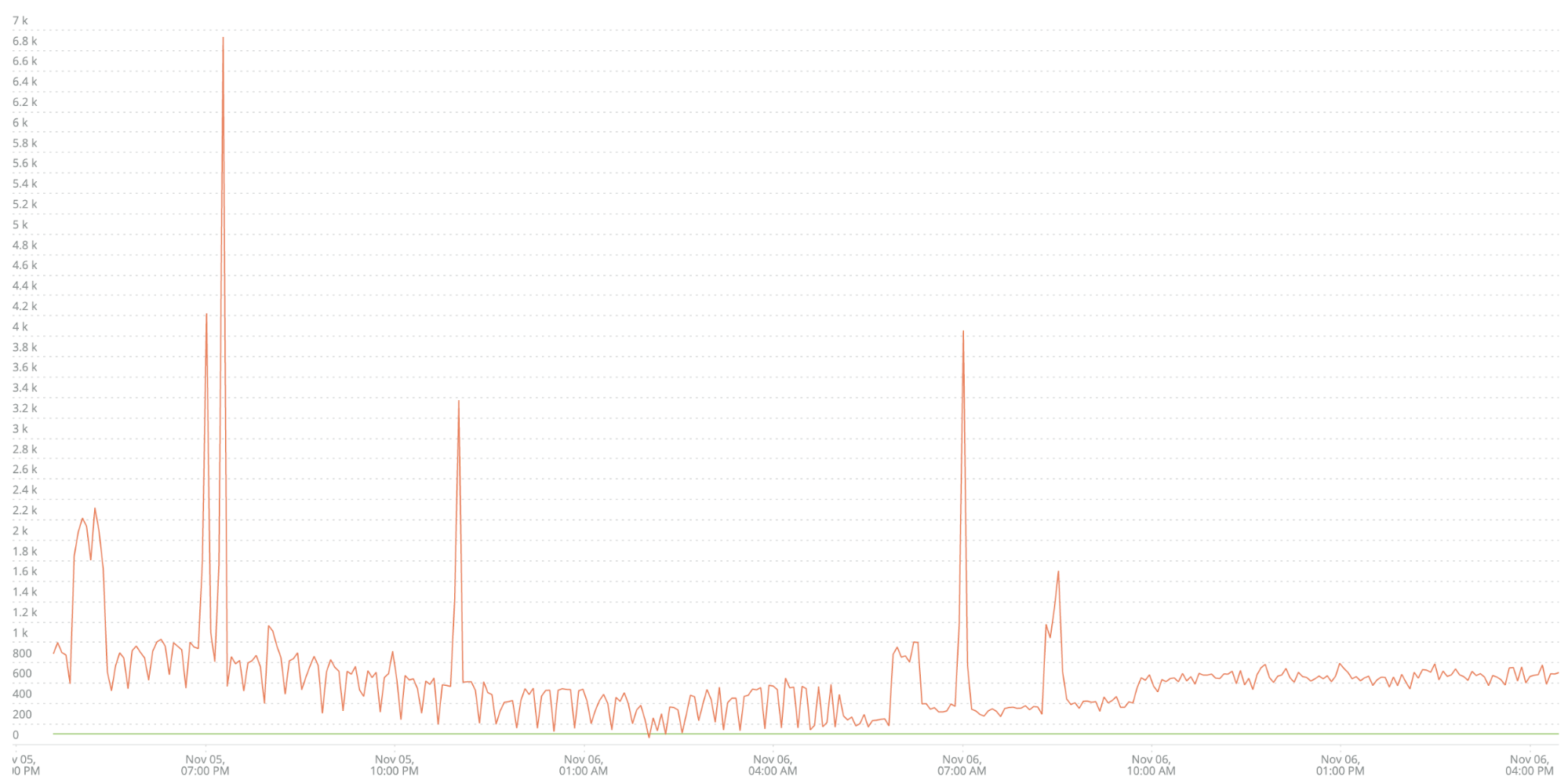
下方にある緑色の水平線は、お客様のアラートの閾値です。ご覧のように、このサービスに対してアラートが継続的に主張されています。そのため、お客様の運用チームはこのアラートに注意を払わなくなりました。これは、質の低いアラートノイズが無視されたわかりやすい例です。
従来の方法では、別の閾値を設定したり、通常のアルゴリズムからの逸脱を調べることに多くの時間を費やしていましたが、それではスピードと品質という2つの重要な要素を測定することができません。ありがたいことに、2つの簡単なステップでここから先に進むことができます。
ステップ1: 品質を測定するためのSLI(エラーのない全トランザクションの割合)を特定します。New Relic のダッシュボードでは、クエリは次のようになります。
FROM Transaction SELECT percentage(count(*), WHERE error IS False) WHERE appName ='b2b-gateway' TIMESERIES MAX SINCE 1 day ago
線の下向きの凹みは、最も大きな問題を示しています。紫の水平線は98%の成功率(SLO)を示しています。このしきい値を下回るものは、警告を必要とする問題です。ここでは、エラーSLIが98%のしきい値を下回る(SLOに違反する)ケースが4つあるので、1日のうちに4つのアラートを受け取ることになります(24×7で警告される1つのアラートとは対照的です)。
あなたは今、大きな目標を達成しました。1回の簡単な操作で、関連性が高く、理解しやすいビジネス指標(「98%のトランザクションにエラーがない」)を作成したのです。さらに、迷惑なアラートを実際のビジネスに影響を与える価値あるアラートに変えたのです。エラーの増加がユーザーエクスペリエンスに直接的な影響を与えることは、明らかであり明白です。
SLIのしきい値を変更することで、この測定値を簡単に大きくしたり小さくしたりすることができます。例えば、まだノイズが多い場合は97%に設定し、改善を促す必要がある場合は99%に設定することができます。
ステップ2: スピード=レスポンスタイムなので、それを加えてみましょう。
例に続けて、B2B-Gatewayのレスポンスタイムの閾値を100ミリ秒(0.1秒)にするとしましょう。(SLOのしきい値の設定方法については、次回のブログ記事をお楽しみに)。
レスポンスタイムを含むようにクエリを変更するには、以下のように変更します。
FROM Transaction SELECT percentage(count(*), WHERE error IS False and duration < 0.1) WHERE appName ='b2b-gateway' TIMESERIES MAX SINCE 1 day ago
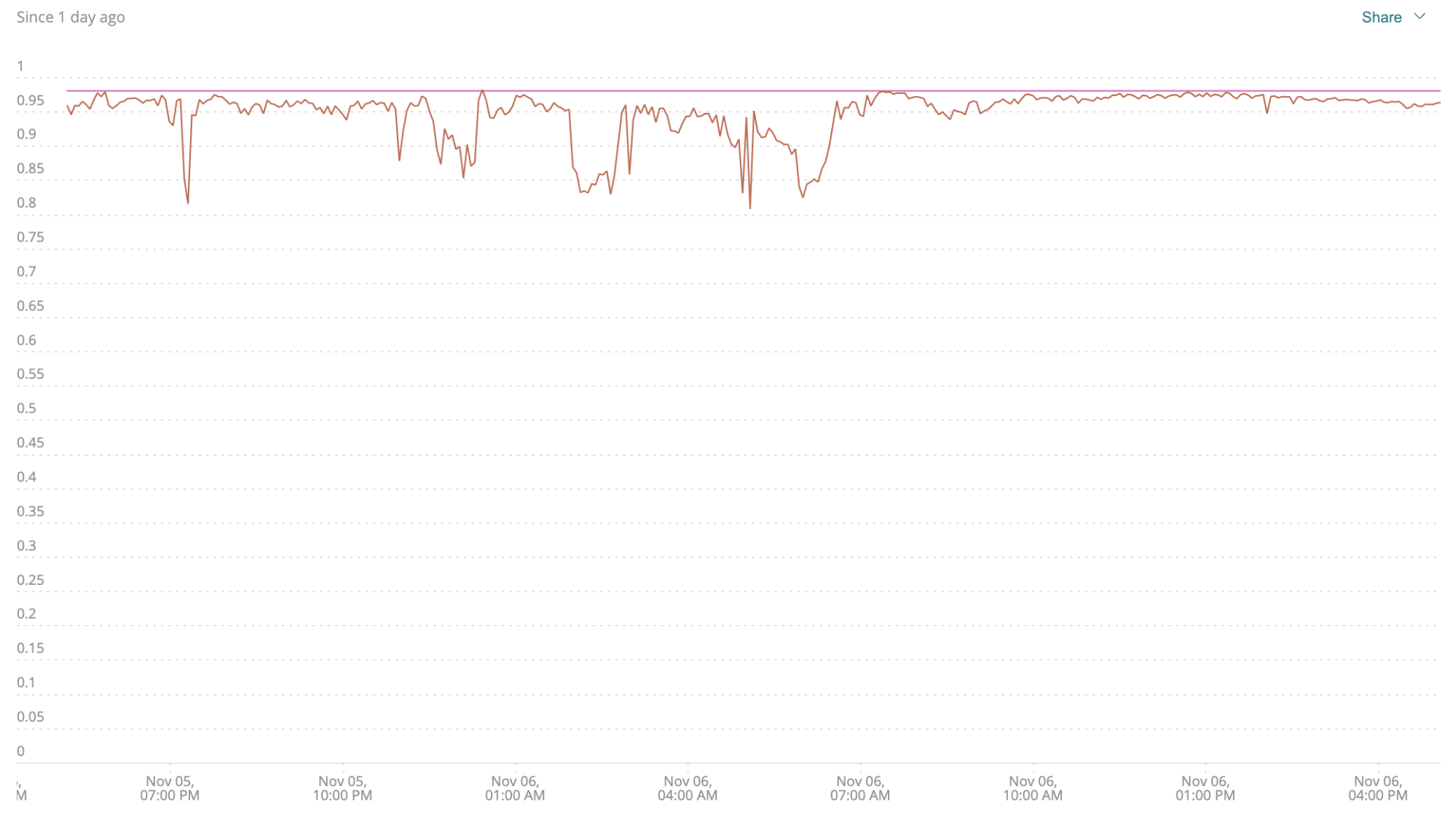
ここでも、下向きの凹みは最も大きな問題を示しており、紫の水平線は98%の閾値を示しています。パフォーマンスを考慮すると、このサービスは思ったほどうまくいっていないことがわかります。品質は良いのですが、サービスはスピードの義務を果たしていません。これは、リソース消費量の指標を見てもわからないことです。これは、リソース消費の指標が「完全に正常」であるIT部門と、サービスが遅いことを耳にするビジネス部門との間の根本的な断絶を解消するのに大きく貢献します-これは大きな勝利です。
最後に、リソース消費量ではなく、スピードと品質を測定することで得られるメリットを確認しましょう。
強力なビジネスアライメント。ビジネスの要件とそれを実現するテクノロジーを真に結びつけるという、簡単で直感的に理解できる指標を手に入れました。このような指標があれば、ビジネスのステークホルダーに対して、「平均して94%しかパフォーマンス義務を満たしていないので、いくつかの変更を行う必要があります」と言うことが非常に容易になります。
問題を表現する明確な指標。SLIはビジネスに影響を与える問題を明らかにします。つまり、実際の問題に早く注意を向けることができ、その結果、問題をより早く解決し、その範囲と深刻さを軽減するためのスタートを切ることができます。また、警告の疲労度を軽減することも忘れてはなりません。
シンプルさ。SLIとSLO(応答時間と品質)は理解しやすく、必要に応じて簡単に修正することができます。
「それはいいけど、次は何をすればいいの?」とおっしゃるかもしれません。まずは、あなたの環境にあるいくつかのサービスを選び、SLI/SLOベースの観測機能を実装し、その結果を既存のモニタリングと比較することから始めてみてください。数週間後には、SLOはより少ない数の重大な問題を検出し、既存の監視では見過ごされていた問題が浮き彫りになることもあるでしょう。
成功を観測可能にするためのチームの構築についてはこちらをご覧ください。
本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


